
บทความโดย
ดร.นรพัชร์ อัศววัลลภ
ดร.สมิทธิ์ธนา ชัยเจนกิจ
ดร.กวิน เอี่ยมตระกูล
1.บทนำ
ในช่วงหลายปีที่ผ่านมา ฐานข้อมูลขนาดใหญ่ (Big Data) ได้กลายเป็นเครื่องมือที่สำคัญในการรวบรวม และเชื่อมโยงข้อมูลที่มีหลากหลายไว้ด้วยกัน ทำให้ผู้ใช้งานสามารถวิเคราะห์ข้อมูลเชิงลึกทั้งในแง่ปริมาณและคุณภาพได้มากขึ้นและรวดเร็ว ประกอบกับความก้าวหน้าทางเทคโนโลยีและปัญญาประดิษฐ์ (Artificial Intelligence) ทำให้ข้อความ (Text Data) มีประโยชน์ในการติดตามสถานการณ์เศรษฐกิจ สังคม และการเมืองเพิ่มมากขึ้น แต่ Text Data ยังมีข้อจำกัด คือ มีโครงสร้างข้อมูลที่ไม่มีรูปแบบที่ชัดเจน (Unstructured Data) ทำให้จำเป็นต้องใช้ Text Mining ในการสกัดข้อความให้เป็นข้อมูลที่เหมาะสมและสามารถวิเคราะห์โดยใช้หลักทางสถิติได้ พร้อมกันนี้ยังจำเป็นต้องใช้ Natural Language Processing (NLP) โดยให้โปรแกรมคอมพิวเตอร์ประมวลผลภาษาที่ประชาชนสื่อสารให้อยู่ในรูปแบบความรู้สึก (Sentiment) และอารมณ์ (Emotion)
ในระยะหลัง งานศึกษาจำนวนมากได้ใช้ประโยชน์จากข้อความ (Text) ทั้งจากหนังสือพิมพ์และสื่อสังคมออนไลน์ สำหรับวิเคราะห์สถานการณ์ทางเศรษฐกิจมากขึ้น เช่น Baker และคณะ (2016)[1] ได้สร้างดัชนีวัดความไม่แน่นอนด้านนโยบายเศรษฐกิจ (Economic Policy Uncertainty) Baker และคณะ (2020)[2] ศึกษาผลกระทบของสถานการณ์ COVID-19 ที่มีต่อตลาดหลักทรัพย์ และ Shihabeldeen (2019)[3] ได้ใช้ความรู้สึกของประชาชน มาคาดการณ์อัตราแลกเปลี่ยน เป็นต้น
นับตั้งแต่ต้นปี 2563 เป็นต้นมา การแพร่ระบาดของโรคติดเชื้อไวรัส COVID-19 ได้ส่งผลกระทบทั้งด้านเศรษฐกิจและสังคมในหลายประเทศ ส่งผลให้ประชาชนได้แสดงความคิดเห็นต่อสถานการณ์ดังกล่าวจำนวนมากผ่านทางสื่อสังคมออนไลน์ โดยเฉพาะในช่วงที่มีการแพร่ระบาดเป็นวงกว้าง โดยงานศึกษาต่างประเทศในระยะแรกที่ใช้ Text Mining ในการวิเคราะห์ทางด้านภาษาศาสตร์และตีความข้อมูล สำหรับติดตามสถานการณ์การแพร่ระบาดของโรคติดเชื้อ (Infectious Diseases) เช่น งานศึกษาของ Jahanbin และคณะ (2017)[4] ได้รวบรวมข้อความ (Text) จากเว็บไซต์ข่าวและ Twitter ที่เกี่ยวข้องกับโรคติดเชื้อทั่วโลก ผลการศึกษาพบว่า ข้อความ Twitter ที่โพสต์เกี่ยวกับโรคหัดและโรคอีโบลามีความสอดคล้องกับจำนวนผู้ป่วยของโรคดังกล่าวที่รายงานใน CDS และ WHO ซึ่งสะท้อนว่าข้อความจาก Twitter มีศักยภาพเพียงพอในการติดตามโรคติดเชื้อ อย่างไรก็ดี งานศึกษานี้ยังมีข้อจำกัด คือ ไม่สามารถใช้ติดตามโรคติดเชื้อในพื้นที่ยากจนและไม่สามารถเข้าถึงเครือข่ายสังคมออนไลน์ได้
นอกจากนี้ Han และคณะ (2020)[5] ได้ใช้ข้อความ (Text) จากการโพสต์ในเว็บไซต์ Weibo (รูปแบบ Twitter ของประเทศจีน) ในช่วงระยะแรกที่ COVID-19 เริ่มระบาด เพื่อวัดความคิดเห็นของประชาชนที่มีต่อโรคดังกล่าว และเมื่อใช้เทคนิค Machine Learning อย่าง Latent Dirichlet Allocation Model and Random Forest ทำให้สามารถจัดหมวดหมู่การโพสต์ได้ ผลการศึกษาพบว่า หัวข้อโพสต์ในเว็บไซต์ Weibo มีความสัมพันธ์กับระดับความรุนแรงของการระบาด COVID-19 ในภาคตะวันออกและภาคกลางของประเทศจีน โดยเฉพาะเมืองอู่ฮั่น ปักกิ่ง เทียนจิน เหอเป่ย และพื้นที่สามเหลี่ยมปากแม่น้ำแยงซีเกียง นอกจากนี้ คณะผู้เขียนยังพบว่า การเปิดเผยข้อมูลเกี่ยวกับการระบาดแบบ Real Time ของรัฐบาล จะมีส่วนสำคัญให้ประชาชนมีความมั่นใจมากขึ้น ทำให้การแสดงความคิดเห็นเริ่มเป็นไปในทิศทางที่ดีขึ้น ดังนั้น Text Mining จึงเป็นเครื่องมือที่มีประโยชน์ ในการช่วยให้รัฐบาลเข้าใจความคิดเห็นของประชาชนมากขึ้นและสามารถดำเนินนโยบายที่ตอบสนองต่อความต้องการของประชาชนได้อย่างทันท่วงที และหากพิจารณาประโยชน์ของ Text Mining และ Natural Language Processing (NLP) ในบริบทของ COVID-19 แล้ว งานศึกษาของ Nguyen (2020)[6] ได้ทบทวนวรรณกรรมที่ประยุกต์ใช้ Text Mining บนเว็บไซต์ Twitter พบว่า สามารถนำมาใช้กับการประมาณการติดเชื้อ และการเปลี่ยนแปลงนโยบายของรัฐบาลเพื่อตอบสนองต่อสถานการณ์การแพร่ระบาดของ COVID-19 ได้เช่นกัน
ทั้งนี้ จากการทบทวนวรรณกรรมต่างประเทศ พบว่า ความคิดเห็นของประชาชนผ่านสื่อสังคมออนไลน์มีประโยชน์ในการติดตามภาวะเศรษฐกิจและสังคม ดังนั้น งานศึกษาฉบับนี้จึงมีวัตถุประสงค์เพื่อใช้ปัญญาประดิษฐ์ (Artificial Intelligence) ในการสร้างแบบจำลอง Logistic Regression สำหรับการวิเคราะห์ความรู้สึก (Sentiment Analysis) ของประชาชนในประเทศไทยที่มีต่อสถานการณ์ COVID-19 ระหว่างวันที่ 1 สิงหาคม 2564 ถึง 28 พฤศจิกายน 2564 ควบคู่ไปกับการสร้างแบบจำลองเชิงเส้นอย่างง่าย (Simple Regression) สำหรับการทดสอบความสัมพันธ์ระหว่างความรู้สึกของประชาชนและเครื่องชี้ทางเศรษฐกิจและสังคม เช่น ดัชนีความเคลื่อนไหว (Google Mobility Index) เครื่องชี้การท่องเที่ยว (Travel Insights with Google) และจำนวนผู้ติดเชื้อ COVID-19 รายใหม่รายวัน
[1] Baker, S. R., Bloom, N., & Davis, S. J. (2016). Measuring economic policy uncertainty. The quarterly journal of economics, 131(4), 1593-1636.
[2] Baker, S. R., Bloom, N., Davis, S. J., Kost, K., Sammon, M., & Viratyosin, T. (2020). The unprecedented stock market reaction to COVID-19. The review of asset pricing studies, 10(4), 742-758
[3] Shihabeldeen, H.Y. (2019). Using Text Mining to Predicate Exchange Rates with Sentiment Indicators. Journal of Business Theory and Practice, 7(2),60-75.
[4] Jahanbin, K., Rahmanian, F., Rahmanian, V., & Jahromi, A. S. (2019). Application of Twitter and web news mining in infectious disease surveillance systems and prospects for public health. GMS hygiene and infection control, 14.
[5] Han, X., Wang, J., Zhang, M., & Wang, X. (2020). Using social media to mine and analyze public opinion related to COVID-19 in China. International Journal of Environmental Research and Public Health, 17(8), 2788.
[6] Nguyen, T. T., Nguyen, Q. V. H., Nguyen, D. T., Hsu, E. B., Yang, S., & Eklund, P. (2020). Artificial intelligence in the battle against coronavirus (COVID-19): a survey and future research directions. arXiv preprint arXiv:2008.07343
2.วิธีการศึกษา
ในลำดับแรกคณะผู้เขียนได้รวบรวมข้อความ (Text) ที่ปรากฏในสื่อสังคมออนไลน์ (Social Media) ได้แก่ Facebook Instagram Twitter Tiktok Website Webboard และ Youtube โดยใช้คำค้นหา (Keyword) คือ COVID และใช้เทคนิค Web Crawler[7] เพื่อดึงข้อมูลอัตโนมัติจากฐานข้อมูลสื่อสังคมออนไลน์ดังกล่าว และใช้เทคนิค Text Mining ในการสกัดข้อมูล ควบคู่ไปกับเทคนิค Natural Language Processing (NLP) ซึ่งเป็นเทคโนโลยีปัญญาประดิษฐ์ (Artificial Intelligence) ที่ใช้โปรแกรมคอมพิวเตอร์แปลภาษาจากข้อความให้ออกมาในรูปแบบความรู้สึก (Sentiment)
ทั้งนี้ คณะผู้เขียนได้ดำเนินการเก็บรวบรวมข้อความตั้งแต่วันที่ 1 สิงหาคม 2564 ถึงวันที่ 28 พฤศจิกายน 2564 จำนวน 338,758 ข้อความ ของประเทศไทย และในขั้นต่อมาได้จัดการข้อความ (Clean Text) ที่โปรแกรมคอมพิวเตอร์ไม่สามารถระบุความรู้สึกได้จำนวน 4,380 ข้อความ และความรู้สึกที่เป็นกลาง (Neutral) จำนวน 173,471 ข้อความ เนื่องจากมีรูปแบบที่ไม่คงที่ ทำให้มีข้อความเหลือทั้งสิ้นจำนวน 160,906 ข้อความ แบ่งเป็นความเห็นต่อ COVID ในทางบวก (Positive) จำนวน 83,314 และทางลบ (Negative) จำนวน 77,565 ข้อความ รายละเอียดดังรูปที่ 1 และหากพิจารณาข้อมูลเป็นรายวันแล้วจะพบว่า ประชาชนกลุ่มตัวอย่างโพสต์ข้อความเกี่ยวกับ COVID-19 ลดลง และการเปลี่ยนแปลงของระดับความรู้สึกรายวัน (Change in Sentiment Level) ก็ลดลงเช่นกัน รายละเอียดดังรูปที่ 2 และ 3 ตามลำดับ สอดคล้องกับจำนวนผู้ติดเชื้อ COVID-19 รายใหม่ ที่ลดลงอย่างต่อเนื่อง หลังจากผ่านจุดสูงสุดจำนวน 23,418 คน ณ วันที่ 13 สิงหาคม 2564 สะท้อนว่าประชาชนมีแนวโน้มที่จะคลายความกังวลจากสถานการณ์ COVID-19 นอกจากนี้ หากพิจารณาประเภทของสังคมออนไลน์ (Social Media) พบว่า ข้อความที่มีผู้ให้ความเห็นสูงสุด 3 อันดับแรก ได้แก่ Facebook Twitter และ Instagram โดยข้อสังเกตที่เห็นได้ชัดเจนคือ ข้อความจาก Instagram จะมีการแสดงความรู้สึกเป็นบวก (Positive) สูงถึงร้อยละ 77.9 ขณะที่ Facebook และ Twitter จะมีการแสดงความรู้สึกเป็นลบ (Negative) สูงกว่าที่ร้อยละ 55.8 และ 53.3 ตามลำดับ รายละเอียดดังรูปที่ 4
[7] ได้รับความอนุเคราะห์ข้อมูลจากศูนย์เทคโนโลยีสารสนเทศและการสื่อสาร สำนักงานปลัดกระทรวงการคลัง

ที่มา: คำนวณโดยคณะผู้เขียน
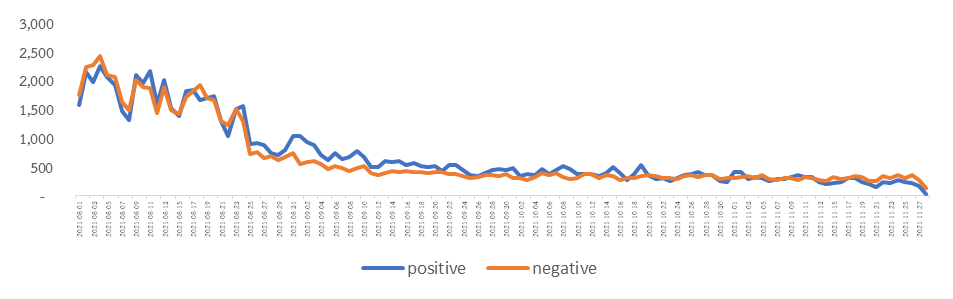
ที่มา: คำนวณโดยคณะผู้เขียน
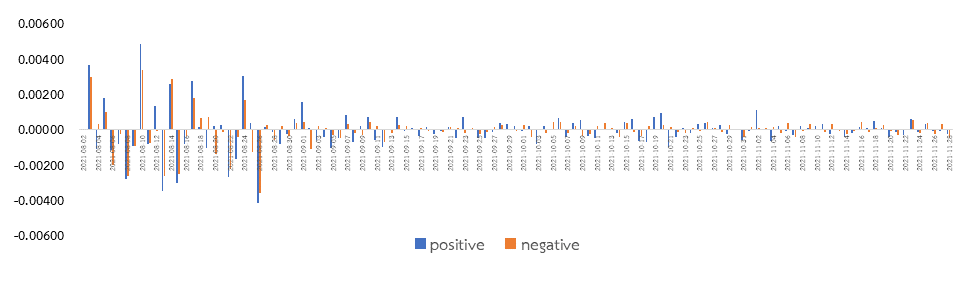
หมายเหตุ: Sentiment Level = จำนวนข้อความของในประเภทความรู้สึก / จำนวนข้อความทั้งหมด
Change in Sentiment Level = Sentiment Level ณ เวลา t – Sentiment Level ณ เวลา t-1
ที่มา: คำนวณโดยคณะผู้เขียน
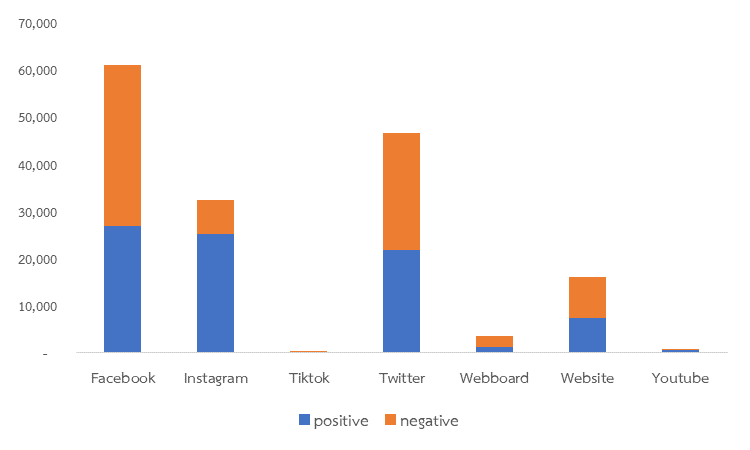
ที่มา: คำนวณโดยคณะผู้เขียน
ในขั้นตอนถัดไป คณะผู้เขียนจะใช้โปรแกรม Python[8] สำหรับการตัดคำ (Word Tokenize) ตัดคำที่เจอบ่อย (Stopword) แต่ไม่ได้สื่อความหมายอะไรมาก เช่น “การ” “ความ” “ที่” “คือ” “ซึ่ง” เป็นต้น และแยกเครื่องหมายวรรคตอน (Punctuation) ออกจากข้อความ พร้อมกับเปลี่ยนข้อความให้มีช่องว่างระหว่างคำ (ให้เหมือนภาษาอังกฤษ) เพื่อนำไปสร้างคำที่มีความถี่ในการใช้บ่อย (Word Cloud) ให้เกิดขึ้นสำหรับใช้ในขั้นตอนต่อไป ซึ่งจะทำให้ทราบว่าคำส่วนใหญ่ที่ปรากฏในข้อความมีอะไรบ้าง ทั้งนี้ หาก Word Cloud มีขนาดใหญ่เท่าไรก็หมายความว่าคำคำนั้นมีความถี่ที่ปรากฏในข้อความจำนวนมาก โดย Word Cloud ของข้อความแสดงความรู้สึกทางบวก (Positive) ส่วนใหญ่จะเป็นคำว่า ตรวจโควิด ชุดตรวจ และหน้ากากอนามัย รายละเอียดดังรูปที่ 5 ขณะที่ Word Cloud ของข้อความแสดงความรู้สึกทางลบ (Negative) ส่วนใหญ่จะเป็นคำว่า ติดเชื้อ เสียชีวิต ผู้ป่วย และระบาด รายละเอียดดังรูปที่ 6
[8] ปรับปรุงการเขียน Code Python จาก Yongsiriwit, K. (2021, May 29). เขียน Python สร้างแบบจำลองการวิเคราะห์รู้สึก (Sentiment Analysis) สำหรับภาษาไทย. https://karnyong.medium.com/เขียน-python-สร้างแบบจำลองการวิเคราะห์รู้สึก-sentiment-analysis-สำหรับภาษาไทย-cdb43de08e9a

ที่มา : คำนวณโดยคณะผู้เขียน

ที่มา : คำนวณโดยคณะผู้เขียน
หลังจากนั้น ก่อนที่จะดำเนินการสร้างแบบจำลองวิเคราะห์ความรู้สึกจากข้อความจำเป็นต้องนับจำนวนคำ (Count) และจัดเก็บในรูปแบบ Vector เมื่อได้จำนวนคำแล้ว จะทำการสร้างคลังคำศัพท์จากข้อความทั้งหมดแต่ละคำ (ที่ไม่ซ้ำกัน) หรือที่เรียกว่า Bag-of-Words (BoW) และต่อมาจะนำข้อความมาจัดเป็นจำนวนคำที่ปรากฏในแต่ละข้อความ รายละเอียดดังตารางที่ 1
| โควิด | ร้ายแรง | ทำให้ | เจ็บป่วย | และ | ตัวร้อน | |
|---|---|---|---|---|---|---|
| โควิดร้ายแรง | 1 | 1 | 0 | 0 | 0 | 0 |
| โควิดทำให้เจ็บป่วย | 1 | 0 | 1 | 1 | 0 | 0 |
| โควิดทำให้ตัวร้อน | 1 | 0 | 1 | 0 | 0 | 1 |
ที่มา : จัดทำโดยคณะผู้เขียน
ในขั้นถัดไปจะสร้างแบบจำลอง Logistic Regression เพื่อทดสอบว่าข้อมูลที่ต้องการฝึกฝน (Train) ว่าสามารถอธิบายข้อมูลที่ต้องการทดสอบ (Test) ได้แม่นยำเพียงใด โดยแบ่งข้อมูลแบ่ง Trainning Set และ Test Set ในสัดส่วนร้อยละ 70: 30 และจะตรวจสอบความถูกต้องและแม่นยำของแบบจำลองดังกล่าว ส่วนขั้นสุดท้ายคณะผู้เขียนจะสร้างแบบจำลองสมการถดถอยอย่างง่าย (Simple Regression) เพื่อทดสอบว่าความรู้สึกของประชาชนที่มีต่อสถานการณ์ COLVID-19 จะสามารถอธิบายตัวแปรทางเศรษฐกิจและสังคม ได้แก่ 1) ดัชนีความเคลื่อนไหว (Google Mobility Index) ในหมวด Retail and Recreation และหมวด Grocery and Pharmacy 2) เครื่องชี้การท่องเที่ยว (Travel Insights with Google) และ 3) จำนวนผู้ติดเชื้อ COVID-19 รายใหม่รายวัน ได้หรือไม่ ทั้งนี้ สรุปขั้นตอนการศึกษาได้ดังรูปที่ 7
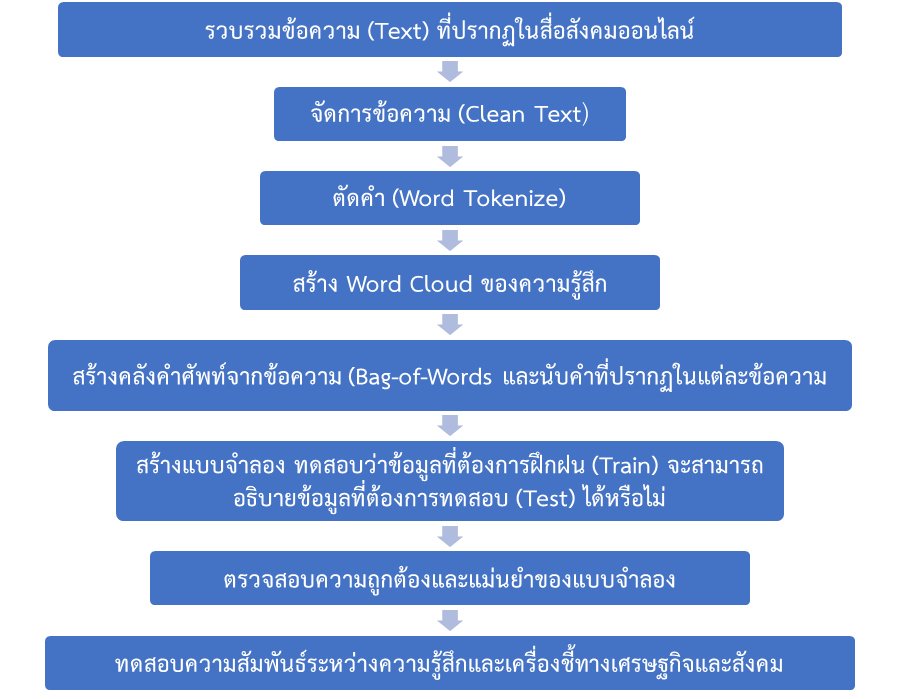
ที่มา: จัดทำโดยคณะผู้เขียน
3.ผลการศึกษา
3.1 แบบจำลอง Logistic Regression
หลังจากแบ่งข้อมูลแบ่ง Trainning Set และ Test Set ในสัดส่วนร้อยละ 70: 30 แล้ว คณะผู้เขียนได้ใช้แบบจำลอง Logistic Regression เพื่อศึกษาว่าตัวแปรข้อความ (Text Data) จะสามารถทำนายความรู้สึกในทางบวกหรือทางลบ ได้หรือไม่ ทั้งนี้ เมื่อนำ Confusion Matrix ซึ่งเป็นเครื่องมือที่ใช้ประเมินผลลัพธ์ของการทำนาย (Prediction) ของแบบจำลองที่สร้างขึ้นกับข้อมูลจริงมาประเมินประสิทธิภาพของการทำนายแบบจำลอง รายละเอียดดังตารางที่ 2 พบว่า ตัวชี้วัดทั้ง 3 ประเภท ได้แก่ 1) Precision 2) Recall และ 3) F1 score สามารถทำนายความรู้สึกทั้งทางบวกและทางลบจากข้อความได้สูงถึงร้อยละ 90 และเมื่อพิจารณาความถูกต้อง (Accuracy) ของแบบจำลองในภาพรวมก็สูงถึงร้อยละ 90 เช่นกัน รายละเอียดดังตารางที่ 3 นอกจากนี้ คณะผู้เขียนได้สร้างข้อความใหม่ขึ้นมา คือ “โครงการดี ช่วยผู้ป่วยโควิด” และ “มีผู้ป่วยจากโควิดจำนวนมาก”เพื่อเป็นการทดสอบแบบจำลอง และก็พบว่าแบบจำลองสามารถทำนายข้อความดังกล่าวได้ว่าเป็นการแสดงความรู้สึกทางบวกและทางลบ ตามลำดับ ดังนั้น การสร้างแบบจำลองเพื่อฝึกฝนข้อมูล (Train) โดยให้โปรแกรมเรียนรู้ว่าข้อความประเภทใดควรจะจัดให้อยู่ในการแสดงความรู้สึกทางบวกหรือทางลบ จึงมีความถูกต้องและแม่นยำในการทำนายความรู้สึกได้สูง
| Actually Positive | Actually Negative | |
|---|---|---|
| Predicted Positive | True Positives (TP) = 21,118 | False Positives (FP) = 2,557 |
| Predicted Negative | False Negatives (FN) = 2,197 | True Negatives (TN) = 22,400 |
หมายเหตุ
True Positive (TP) คือ การทำนายว่าจริง และสิ่งที่เกิดขึ้น ก็คือ จริง
True Negative (TN) คือ การทำนายว่า ไม่จริง และสิ่งที่เกิดขึ้น ก็คือ ไม่จริง
False Positive (FP) คือ การทำนายว่า จริง แต่สิ่งที่เกิดขึ้น คือ ไม่จริง
False Negative (FN) คือ การทำนายว่าไม่จริง แต่สิ่งที่เกิดขึ้น คือ จริง
โดย TP TN FP FN ในตารางจะแทนด้วยค่าความถี่ของการทำนาย
ที่มา : จัดทำโดยคณะผู้เขียน
| Precision | Recall | F1 score | |
|---|---|---|---|
| Positive | 0.89 | 0.91 | 0.90 |
| Negative | 0.91 | 0.90 | 0.90 |
หมายเหตุ นิยามนำมาจาก Gatchalee (2019)
Precision คือ การเปรียบเทียบการทำนายที่ถูกต้องว่า จริง และก็เกิดขึ้นจริง (TP) กับ การทำนายว่า จริง แต่สิ่งที่เกิดขึ้น คือ ไม่จริง (FP) Precision = TP / (TP + FP)
Recall คือ ความถูกต้องของการทำนายว่าจะเป็น “จริง” เทียบกับ จำนวนครั้งของเหตุการณ์ทั้งทำนาย และเกิดขึ้นว่า “เป็นจริง”
Recall = TP/(TP+FN)
F1 score คือ ค่าเฉลี่ยระหว่าง Precision และ Recall เพื่อวัดความสามารถของแบบจำลอง
F1 = 2 x (Precision x Recall)/(Precision + Recall)
Accuracy คือ ความถูกต้องของข้อมูลที่ทำนายกับที่เกิดขึ้นจริง
Accuracy = (TP + TN) / (TP+TN+FP + FN)
ที่มา : จัดทำโดยคณะผู้เขียน
3.2 การทดสอบความสัมพันธ์ระหว่างความรู้สึกและเครื่องชี้เศรษฐกิจและสังคม
ในลำดับถัดไป คณะผู้เขียนจะทดสอบความสัมพันธ์ระหว่างจำนวนความรู้สึกทั้งหมด (Total Sentiment) ของประชาชนในประเทศไทยที่มีต่อสถานการณ์ COVID-19 กับเครื่องชี้เศรษฐกิจและสังคมที่เกี่ยวข้อง ได้แก่ 1) ดัชนีความเคลื่อนไหว (Google Mobility Index) ในหมวด Retail and Recreation และหมวด Grocery and Pharmacy 2) เครื่องชี้การท่องเที่ยว (Travel Insights with Google) และ 3) จำนวนผู้ติดเชื้อ COVID-19 รายใหม่รายวัน โดยคำนวณ Robust Standard Error และใช้เกณฑ์ในการเลือกแบบจำลองที่แสดงค่า Akaike Infomration Criterion (AIC) ต่ำที่สุด รายละเอียดดังนี้
| ตัวแปรตาม (Y) : เครื่องชี้เศรษฐกิจและสังคม | Retail and Recreation | Grocery and Pharmacy | Travel Insights with Google | จำนวนผู้ติดเชื้อ COVID-19 |
|---|---|---|---|---|
| ตัวแปรอิสระ (X) : จำนวนความรู้สึกทั้งหมด (Total Sentiment) | -0.0077*** | -0.0046*** | -0.0127*** | 3.0570*** |
| R-square | 0.6395 | 0.3819 | 0.6853 | 0.7616 |
AIC ต่ำสุดของจำนวนความรู้สึกที่ทดสอบกับ Google Mobility Index ในหมวด Retail and Recreation และหมวด Grocery and Pharmacy และ 2) Travel Insights with Google คือ ณ ช่วงเวลา t-3
AIC ต่ำสุดของจำนวนความรู้สึกที่ทดสอบกับจำนวนผู้ติดเชื้อโควิด-19 คือ ณ ช่วงเวลา t-4
ที่มา คำนวณโดยคณะผู้เขียน
จากตารางที่ 4 จะพบว่าจำนวนความรู้สึกทั้งหมด (Total Sentiment) มีความสัมพันธ์อย่างมีนัยสำคัญทางสถิติที่ระดับร้อยละ 99 กับเครื่องชี้ทางเศรษฐกิจและสังคมที่นำมาทดสอบทั้ง 4 เครื่องชี้ โดยมีความสัมพันธ์ในทิศทางตรงกันข้ามกับดัชนีความเคลื่อนไหวของ Google ในหมวด Retail and Recreation และหมวด Grocery and Pharmacy และเครื่องชี้การท่องเที่ยว (Travel Insights with Google) ตัวอย่างเช่น หากประชาชนที่แสดงความคิดเห็นต่อสถานการณ์ COVID-19 ผ่านสื่อสังคมออนไลน์เพิ่มขึ้น 1 ครั้ง ในช่วง 3 วันก่อนหน้า จะส่งผลให้การเคลื่อนที่ของประชาชนผ่านการเรียกใช้งานแผนที่ Google Map ไปยังสถานที่ Retail and Recreation ในช่วงเวลาปัจจุบัน โดยเฉลี่ยลดลงร้อยละ 0.0077 อย่างไรก็ดี จำนวนความรู้สึกทั้งหมด (Total Sentiment) มีความสัมพันธ์ในทิศทางเดียวกันกับจำนวนผู้ติดเชื้อ COVID-19 โดยความคิดเห็นของประชาชนที่มีต่อ COVID-19 ผ่านสื่อสังคมเพิ่มขึ้น 1 ครั้ง ในช่วง 4 วันก่อนหน้า จะทำให้จำนวนผู้ติดเชื้อในปัจจุบันเพิ่มขึ้นประมาณ 3 คนโดยเฉลี่ย
|
ตัวแปรตาม (Y) : |
Retail and |
Grocery and Pharmacy |
Travel Insights |
จำนวนผู้ติดเชื้อ |
|
ตัวแปรอิสระ (X) : จำนวนความรู้สึกทั้งหมด (Total Sentiment) |
||||
|
R-square |
-0.0169*** 0.6322 |
-0.0101*** 0.3719 |
-0.0275*** 0.6651 |
6.590*** 0.7290 |
|
R-square |
-0.0469*** 0.7659 |
-0.0303*** 0.5279 |
-0.0770*** 0.8201 |
18.40*** 0.8906 |
|
R-square |
-0.0279*** 0.6778 |
-0.0171*** 0.4207 |
-0.0460*** 0.7431 |
11.17*** 0.8253 |
หมายเหตุ ***. **, * ระดับนัยสำคัญทางสถิติที่ร้อยละ 99 95 และ 90 ตามลำดับ
AIC ต่ำสุดของจำนวนความรู้สึกของ Facebook และ Twitter ที่ทดสอบกับ Retail and Creation คือ ณ ช่วงเวลา t-3 ขณะที่ จำนวนความรู้สึกของ Instagram คือ ณ ช่วงเวลา t-2
AIC ต่ำสุดของจำนวนความรู้สึกของ Facebook Instagram และ Twitter ที่ทดสอบกับ Grocery and Pharmacy คือ ณ ช่วงเวลา t-3
AIC ต่ำสุดของจำนวนความรู้สึกของ Facebook และ Instagram ที่ทดสอบกับ Travel Insights with Google คือ ณ ช่วงเวลา t-3 ขณะที่ จำนวนความรู้สึกของ Twitter คือ ณ ช่วงเวลา t-4
AIC ต่ำสุดของจำนวนความรู้สึกที่ทดสอบกับจำนวนผู้ติดเชื้อ COVID-19 คือ ณ ช่วงเวลา t-4
ที่มา คำนวณโดยคณะผู้เขียน
นอกจากนี้ เมื่อพิจารณาจำแนกตามประเภทสื่อสังคมออนไลน์ก็ได้ผลลัพธ์ที่สอดคล้องกับการวิเคราะห์ในภาพรวม แต่มีข้อสังเกตที่สำคัญคือ ค่าสัมประสิทธิ์สหสัมพันธ์ (Correlation) ของผู้ใช้งาน Instagram จะมีค่าสูงกว่าผู้ใช้งาน Facebook และ Twitter โดยเฉพาะเมื่อผู้ใช้งาน Instagram ให้ความคิดเห็นเพิ่มขึ้น 1 ครั้ง จะส่งผลให้จำนวนผู้ติดเชื้อ COVID-19 รายใหม่ โดยเฉลี่ยเพิ่มขึ้น 18 คน
อย่างไรก็ดี งานศึกษาฉบับนี้ยังมีข้อจำกัด คือ เมื่อพิจารณาแยกการทดสอบจำนวนความรู้สึกเป็นทั้งทางบวกและทางลบ จะพบว่ามีทิศทางของความสัมพันธ์ตรงกันข้ามกับสมมุติฐานที่ตั้งไว้ นั้นคือ ถ้าผู้ใช้งานในสื่อสังคมออนไลน์แสดงความรู้สึกทางบวกเพิ่มขึ้น ทำให้การเคลื่อนที่เดินทางลดลงและจำนวนผู้ติดเชื้อเพิ่มขึ้น ในทางตรงกันข้าม การแสดงความรู้สึกทางลบ กลับทำให้การเคลื่อนที่เดินทางเพิ่มขึ้นและจำนวนผู้ติดเชื้อลดลง ดังนั้น งานศึกษาในอนาคตอาจต้องเพิ่มช่วงเวลาทำการศึกษาให้มากขึ้น หรือมีคำค้นหาอื่นที่อาจเกี่ยวข้องกับ COVID-19 มาใช้ทดสอบให้มากขึ้น
4. บทสรุป
งานศึกษาฉบับนี้มีวัตถุประสงค์เพื่อใช้ปัญญาประดิษฐ์ (Artificial Intelligence) ในการสร้างแบบจำลอง Logistic Regression สำหรับการวิเคราะห์ความรู้สึก (Sentiment Analysis) ของประชาชนในประเทศไทยที่มีต่อสถานการณ์ COVID-19 ระหว่างวันที่ 1 สิงหาคม 2564 ถึง 28 พฤศจิกายน 2564 ควบคู่ไปกับการสร้างแบบจำลองเชิงเส้นอย่างง่าย (Simple Regression) สำหรับการทดสอบความสัมพันธ์ระหว่างความรู้สึกของประชาชนและเครื่องชี้ทางเศรษฐกิจและสังคม เช่น ดัชนีความเคลื่อนไหว (Google Mobility Index) เครื่องชี้การท่องเที่ยว (Travel Insights with Google) และจำนวนผู้ติดเชื้อ COVID-19 รายใหม่รายวัน ผลการศึกษาพบว่า แบบจำลอง Logistic Regression เมื่อนำข้อมูลมาฝึกฝน (Train) ให้โปรแกรมเรียนรู้ว่าข้อความประเภทใดควรจะจัดให้อยู่ในการแสดงความรู้สึกทางบวกหรือทางลบ จะสามารถอธิบายข้อมูลที่ต้องการทดสอบ (Test) ได้ถูกต้องและแม่นถึงร้อยละ 90 และในส่วนของการทดสอบด้วยแบบจำลองเชิงเส้นอย่างง่าย พบว่า จำนวนความรู้สึกมีความสัมพันธ์ในทางตรงกันข้ามกับดัชนีความเคลื่อนไหวของ (Google Mobility Index) และเครื่องชี้การท่องเที่ยว (Travel Insights with Google) ขณะที่มีความสัมพันธ์ในทิศทางเดียวกันกับจำนวนผู้ติดเชื้อ COVID-19 รายวัน ไม่ว่าจะทดสอบในภาพรวมหรือจำแนกตามประเภทสื่อสังคมออนไลน์




ดร.กวิน เอี่ยมตระกูล
ผู้เขียน