
บทความโดย
นางสาวกานต์สินี เจริญกิจวัชรชัย
ผศ.ดร.ณัฐพงษ์ พัฒนพงษ์
ผศ.ดร.มณเฑียร สติมานนท์
บทคัดย่อ
อัตราค่าจ้างนั้นมีความสำคัญในทางเศรษฐศาสตร์โดยมีความเชื่อมโยงกับหลายกลุ่ม ทั้งในส่วนของลูกจ้าง ผู้ประกอบการ และผลต่อเศรษฐกิจโดยรวม ดังนั้นกลไกการกำหนดค่าจ้างจึงถือว่ามีความสำคัญต่อระบบเศรษฐกิจ การศึกษาครั้งนี้มุ่งศึกษาถึงปัจจัยที่มีอิทธิพลในการกำหนดค่าจ้างแรงงานไทยในช่วง ปี พ.ศ. 2550 – 2560 โดยศึกษาจากข้อมูลการสำรวจภาวะเศรษฐกิจและสังคมของครัวเรือน (SES) และข้อมูลการสำรวจภาวะการทำงานของประชากร (LFS) และสร้างสมการแบบจำลองพยากรณ์ค่าจ้างแรงงาน โดยใช้วิธีการทางเศรษฐมิติ และเทคนิควิธีการทางปัญญาประดิษฐ์ ซึ่งได้แก่ อัลกอริทึมโครงข่ายประสาทเทียม (Artificial Neural Network) และอัลกอริทึม Random Forest เพื่อเปรียบเทียบประสิทธิภาพในการพยากรณ์
ผลการศึกษาพบว่า ปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างแรงงานในช่วง 10 ปีที่ผ่านมา ประกอบไปด้วย 3 ปัจจัยหลัก คือปัจจัยด้านคุณลักษณะทั่วไปของแรงงาน ปัจจัยที่เกี่ยวข้องกับอาชีพและกิจการ และปัจจัยทางด้านภูมิศาสตร์ โดยผลจากการพยากรณ์พบว่า แบบจำลองทางปัญญาประดิษฐ์ในส่วนของอัลกอริทึม Random Forest มีความแม่นยำในการพยากรณ์มากกว่าแบบจำลองเศรษฐมิติ และสามารถบอกถึงระดับความสำคัญของแต่ละปัจจัยต่อการกำหนดค่าจ้างแรงงานได้เช่นเดียวกับแบบจำลองเศรษฐมิติ ในขณะที่แบบจำลองทางปัญญาประดิษฐ์อัลกอริทึมโครงข่ายประสาทเทียมนั้น ถึงแม้ว่ามีความแม่นยำสูงกว่าแบบจำลองเศรษฐมิติ แต่ยังมีข้อจำกัดด้านความสามารถในการอธิบายผลของแบบจำลองและการประมวลผลข้อมูลที่ประกอบด้วยตัวแปรแบบ discrete จำนวนมาก โดยผลที่ได้จากงานวิจัยนี้แสดงถึงศักยภาพของการประยุกต์ใช้เทคนิควิธีการทางปัญญาประดิษฐ์ในทางเศรษฐศาสตร์ในอนาคต
หมายเหตุ: บทความนี้เป็นผลงานสืบเนื่องจากการค้นคว้าอิสระ หลักสูตรปริญญาโทเศรษฐศาสตร์ธุรกิจ คณะเศรษฐศาสตร์ มหาวิทยาลัยธรรมศาสตร์ และได้รับรางวัลรองชนะเลิศอันดับ 1 ในโครงการเศรษฐทัศน์ ประจำปี 2564
ABSTRACT
A wage is one of key factors enabling economic expansion. It is related to many economic agents such as employees, entrepreneurs and the rest of the economy. Therefore, the behavior of entrepreneur’s wage determination should be thoroughly considered. This research aims to study factors influencing the determination of wages in Thai labor market during 2007 – 2017 by using nationwide official data of Household Socio-Economic Survey (SES) and Labor Force Survey (LFS). This study also formulates the forecasting model of Thai labor wages by using the regression method and Artificial Intelligence (AI) techniques, which are the Artificial Neural Network (ANN) framework and the Random Forest (RF) algorithm.
The outcome of this study indicates that determinants influencing the wage determination in the last 10 years comprise of three main factors, which are (1) personal attributes, (2) career and business characteristics and (3) geographical indictors. Moreover, it is found that Random Forest algorithm is the most accurate forecasting method, and it also allows the computation of degree of significance of each factor. Although ANN framework is more accurate than the regression method, there are limitations in its ability to explain the detail of causality and there is still a limitation in processing dataset that includes many discrete variables. These findings suggest the future extension of applying artificial intelligence techniques in examining and forecasting key economic indicators.
Keywords: Artificial intelligence, Human resource management, Wages Forecasting, Neural Network algorithm, Random Forest algorithm, Thai economy
1. ที่มาและความสำคัญ
แรงงานถือว่าเป็นปัจจัยการผลิต และเป็นเครื่องสะท้อนศักยภาพของทุนมนุษย์ที่มีความสำคัญมากต่อการพัฒนาเศรษฐกิจและการพัฒนาประเทศ นอกจากนี้แรงงานในภาคการผลิตยังคงมีบทบาทในการเป็นผู้บริโภคในการซื้อสินค้าและบริการในตลาดผลผลิต โดยเมื่อพิจารณากลไกของระบบเศรษฐกิจ การจ่ายค่าจ้างของหน่วยผลิตนั้นในทางหนึ่งถือว่าเป็นต้นทุนของภาค การผลิต และในอีกทางหนึ่งจะเข้าสู่วงจรเศรษฐกิจของประเทศผ่านรายได้ของแรงงานและทำให้เกิดการบริโภคของแรงงาน (Consumption) และซึ่งทำให้เกิดความต้องการสินค้าและบริการมากขึ้น และส่งผลทำให้เกิดการขยายตัวของภาคการผลิต (Investment) ซึ่งในท้ายที่สุดจะส่งผลสืบเนื่องทำให้เกิดการขยายตัวของผลิตภัณฑ์มวลรวมประเทศ (Gross Domestic Product: GDP) ดังนั้น จึงกล่าวได้ว่าค่าจ้างนั้นมีความสำคัญต่อระบบเศรษฐกิจ โดยทำให้เกิดกลไกความเชื่อมโยงกับ หลายกลุ่ม กล่าวคือ มีผลต่อลูกจ้างในด้านของรายได้ มีผลต่อผู้ประกอบการในด้านของต้นทุนค่าจ้าง และมีผลต่อเศรษฐกิจโดยรวมทั้งต่อราคาสินค้า การพัฒนาประสิทธิภาพของแรงงานและการลงทุน ดังนั้นกลไกการกำหนดค่าจ้างของผู้ประกอบการ จึงถือว่ามีความสำคัญทั้งต่อแรงงาน ผู้ประกอบการ และเศรษฐกิจโดยรวม
ปัจจุบันประชากรในประเทศไทยเมื่อสิ้นปี พ.ศ. 2560[1] มีจำนวนทั้งสิ้น 66.19 ล้านคน โดยเป็นผู้ที่มีอายุ 15 ปีขึ้นไป มีจํานวน 55.96 ล้านคน โดยเป็นผู้อยู่ในกําลังแรงงานหรือผู้ที่พร้อมจะทํางาน 38.10 ล้านคน (ร้อยละ 68.1) ซึ่งประกอบด้วย ผู้มีงานทํา 37.46 ล้านคน โดยในช่วง 10 ปีที่ผ่านมา (พ.ศ. 2550 – 2560) นั้น รายได้จากการทำงาน ถือเป็นสัดส่วนที่สำคัญต่อรายได้ของแรงงานไทยคิดเป็นร้อยละ 73.28 ของแรงงานทั้งหมด โดยรายได้เฉลี่ยของแรงงานไทยอยู่ที่ 11,108.30 บาทต่อคนต่อเดือน นอกจากนี้ ค่าจ้างยังเป็นเรื่องสำคัญในการทำให้เกิดอำนาจซื้อของผู้บริโภคในระบบเศรษฐกิจ ซึ่งจากข้อมูลการสำรวจของสำนักงานสถิติแห่งชาติ พบว่าค่าใช้จ่ายเฉลี่ยต่อครัวเรือนมีมูลค่า 18,484 บาทต่อเดือน โดยกว่าร้อยละ 87.89 ของรายได้ ถูกนำไปใช้เพื่อการอุปโภคและบริโภค ซึ่งจากพื้นฐานของทฤษฎีดุลยภาพทั่วไป หากค่าจ้างเพิ่มขึ้นสูงกว่าระดับราคาสินค้าและบริการ ก็จะทำให้เกิดการเพิ่มขึ้นของอำนาจซื้อของแรงงาน หรือทำให้อุปสงค์โดยรวมเพิ่มขึ้น
[1] ข้อมูลจากสำนักงานสถิติแห่งชาติ (http://statbbi.nso.go.th/staticreport/page/sector/th/01.aspx)
นอกจากผลกระทบของการจ่ายค่าจ้างแรงงานที่ส่งผลต่อภาพรวมของระบบเศรษฐกิจและความเป็นอยู่ของประชาชนในระดับประเทศแล้ว ในระดับขององค์กรหรือสถานประกอบการ อาจจะได้รับผลกระทบจากเรื่องการจ่ายค่าจ้างด้วยเช่นกัน เนื่องจากค่าจ้างที่จ่ายนั้นจะทำให้องค์การสามารถดึงดูดบุคลากรผู้มีความสามารถสูงเข้ามาสู่องค์การ (เจษฎา, 2550) นอกจากนี้ยังเป็นต้นทุนที่สำคัญมีสัดส่วนประมาณร้อยละ 15 ของมูลค่าผลผลิต รองจากต้นทุนวัตถุดิบที่ร้อยละ 50 และจะยิ่งมีความสำคัญมากขึ้น หากผู้ประกอบการอยู่ในอุตสาหกรรมที่ใช้แรงงานเข้มข้น ซึ่งก็จะส่งผลกระทบต่ออุปทานแรงงานในตลาดแรงงาน (เสาวณี และ ปาณิศาร์, 2558)
ดังนั้นการให้ความสำคัญกับการจ่ายค่าตอบแทนที่เหมาะสมให้แก่พนักงานจึงมีความสำคัญยิ่ง โดยการกำหนดราคาที่เหมาะสมสำหรับแต่ละองค์กรนั้น ขึ้นอยู่กับกลไกตลาดตามหลักเศรษฐศาสตร์ ซึ่งตั้งอยู่บนพื้นฐานตลาดแรงงานที่นายจ้างแข่งขันกันเสนอราคาและลูกจ้างจะสามารถเลือกนายจ้างที่ตนเองพอใจทำงาน ณ ระดับอัตราค่าจ้างดุลยภาพ สิ่งสำคัญสิ่งหนึ่งคือการมีข้อมูลข่าวสารที่สมมาตร (Symmetric Information) ระหว่างแรงงานและสถานประกอบการ เพื่อให้ทราบข้อมูลเพื่อช่วยในการตัดสินใจได้ดียิ่งขึ้น
จากเหตุผลที่กล่าวมาข้างต้น ผู้วิจัยจึงเล็งเห็นว่าจะเป็นประโยชน์อย่างมาก หากมีการพัฒนาแบบจำลองที่สามารถพยากรณ์ค่าจ้างกลางของตลาดแรงงาน เพื่อเป็นข้อมูลสำหรับสถานประกอบการในการกำหนดอัตราค่าจ้างเบื้องต้นที่สอดคล้องกับตลาดแรงงาน และเป็นข้อมูลสำหรับแรงงานเพื่อทราบราคากลางของค่าจ้างในตลาดแรงงาน ซึ่งจะช่วยเพิ่มอำนาจของแรงงาน ในการต่อรองกับผู้ประกอบการและยังช่วยกระตุ้นให้แรงงานพัฒนาตนเองเพื่อให้สามารถมีค่าจ้างเพิ่มขึ้นได้ ซึ่งแบบจำลองสามารถพัฒนาโดยใช้วิธีการดั้งเดิม คือ วิธีการทางเศรษฐมิติ และการใช้เทคโนโลยีปัญญาประดิษฐ์ (Artificial Intelligence) ในการเพิ่มประสิทธิภาพแบบจำลองให้มีความแม่นยำมากยิ่งขึ้น
ดังนั้น ในงานวิจัยนี้ผู้วิจัยจึงทำการศึกษาและพัฒนาแบบจำลองการกำหนดค่าจ้างแรงงานของแรงงานไทยที่มีความแม่นยำ และได้เปรียบเทียบความแม่นยำระหว่างเครื่องมือทางเศรษฐมิติเดิมกับเครื่องมือเทคโนโลยีปัญญาประดิษฐ์ เพื่อเป็นแนวทางสำหรับการนำมาใช้ประโยชน์ทั้งแรงงานและสถานประกอบการทั้งภาครัฐและเอกชนในอนาคต
2. วัตถุประสงค์การศึกษา
(1) เพื่อศึกษาและรวบรวมปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างของแรงงานไทย กรณีศึกษาช่วงระหว่าง พ.ศ. 2550 – 2560
(2) เพื่อสร้างแบบจำลองแสดงการกำหนดค่าจ้างแรงงานไทยตามปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างของแรงงาน โดยใช้วิธีการทางเศรษฐมิติและวิธีการทางปัญญาประดิษฐ์ และเปรียบเทียบระดับความแม่นยำของผลการพยากรณ์ เพื่อระบุแบบจำลองที่เหมาะสมที่สุดในการประยุกต์ใช้
3. แนวคิดทางทฤษฎีที่เกี่ยวข้อง
แนวคิดและทฤษฎีที่ใช้ในการศึกษาครั้งนี้ แบ่งออกเป็นสองประเภทด้วยกัน ได้แก่ (1) การพิจารณาปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างแรงงาน โดยแนวคิดในการศึกษาปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างแรงงาน ได้แก่ ทฤษฎีสมการรายได้ของมินเซอร์ (Mincerian Earnings Function) โดยเป็นการศึกษาปัจจัยที่มีอิทธิพลต่อแรงงาน คือ จำนวนปีการศึกษา, จำนวนปีประสบการณ์ในการทำงาน และรายได้ (Mincer, 1974) โดยพบความสัมพันธ์ทางบวกระหว่างค่าจ้างกับจำนวนปีการศึกษา และประสบการณ์ในการทำงาน
(2) การสร้างแบบจำลองหรือสมการการกำหนดค่าจ้างแรงงานนั้นมีทฤษฏีที่เกี่ยวข้อง เช่น การสร้างแบบจำลองทางเศรษฐมิติด้วยการวิเคราะห์สมการถดถอยเชิงเส้น (Linear Regression) ที่แสดงความสัมพันธ์ระหว่างตัวแปรอิสระ (Independent Variable) ซึ่งแสดงคุณลักษณะต่างๆ ของแรงงานและผู้ประกอบ และตัวแปรตาม (Dependent Variable) ซึ่งเป็นค่าจ้างที่เปลี่ยนแปลงไปตามค่าของชุดตัวแปรอิสระ
นอกจากนี้ ในปัจจุบันได้มีองค์ความรู้ใหม่ๆ เช่น เทคนิควิธีทางด้านปัญญาประดิษฐ์ที่พัฒนาขึ้น ทำให้การพยากรณ์มีความแม่นยำมากขึ้นและสามารถรองรับความซับซ้อนของปัจจัยที่มีผลต่อค่าพยากรณ์ได้มากขึ้น โดยวิธีด้านปัญญาประดิษฐ์ (Artificial Intelligence) นั้น เป็นศาสตร์แขนงหนึ่งของวิทยาศาสตร์คอมพิวเตอร์ ที่เกี่ยวข้องกับวิธีการทำให้คอมพิวเตอร์มีความสามารถคล้ายมนุษย์หรือเลียนแบบพฤติกรรมมนุษย์ โดยการพัฒนาอัลกอริทึมและโปรแกรมคอมพิวเตอร์ที่ทำให้คอมพิวเตอร์มีความสามารถในการคิดเองได้ โดยในสาขาหนึ่งของวิธีด้านปัญญาประดิษฐ์ (Artificial Intelligence) คือ การทำให้คอมพิวเตอร์เกิดกระบวนการเรียนรู้และพัฒนาความสามารถในการแยกแยะผลหรือพัฒนากระบวนการสำหรับการพยากรณ์ผล ซึ่งวิธีการนี้เรียกว่า Machine Learning (บุญเสริม, 2548) โดย Machine Learning อัลกอริทึมนั้นมีความหลากหลายของรูปแบบการทำงาน ตลอดจนคุณภาพความแม่นยำที่แตกต่างกันไป
สำหรับงานวิจัยนี้ จะเลือกใช้เทคนิควิธีที่เป็นที่นิยมและได้รับการยอมรับว่ามีความแม่นยำระดับสูง จำนวน 2 วิธี จากกลุ่ม Machine Learning ประเภท Supervised Learning คือ เทคนิคโครงข่ายประสาทเทียม (Artificial Neural Networks: ANN) และเทคนิควิธี Random Forest ซึ่งเป็นกลุ่มของอัลกอริทึมที่มีลักษณะการทำนายผลลัพธ์ (Forecasting) โดยให้คอมพิวเตอร์สร้างกระบวนการพยากรณ์ด้วยตัวเองจากข้อมูลที่จัดไว้ให้ จนมีระดับความแม่นยำของการพยากรณ์สูงขึ้นต่อเนื่อง โดยรายละเอียดของทั้ง 2 วิธี มีลักษณะดังนี้
(2.1) เทคนิคโครงข่ายประสาทเทียม
(Artificial Neural Networks, ANN) เป็นตัวแบบทางคณิตศาสตร์ที่จำลองการทำงานของสมองมนุษย์ในการเรียนรู้และจดจำด้วย การทำงานแบบเชื่อมต่อ (Connectionist) โดยการนำข้อมูลต่างๆ มาประมวลผล วิเคราะห์ ตีความ และผลลัพธ์ที่ได้เรียกว่า ความรู้ (Knowledge) อันเกิดจากกระบวนการเรียนรู้ โดยทั่วไปเซลล์ประสาทของ ANN ถูกจำลองโดยเมื่อมีข้อมูลนำเข้า (Input) ส่งเข้ามาก็จะคูณกับค่าน้ำหนัก (Weight) ซึ่งแทนความสำคัญที่ให้กับข้อมูลนำเข้าแต่ละตัว ผลรวมของค่าถ่วงน้ำหนักที่เกิดจากผลคูณของข้อมูลนำเข้าและค่าน้ำหนักจะถูกนำไปวิเคราะห์ ตีความโดยฟังก์ชันกระตุ้น (Activation Function) เกิดเป็นผลลัพธ์ (Output) ซึ่งแสดงดังภาพที่ 1
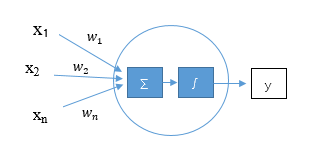
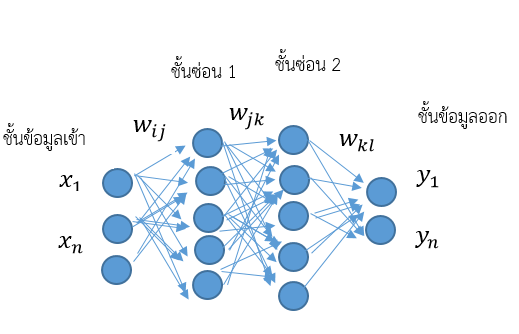
ในการนำ ANN มาใช้ในการพยากรณ์นั้น โครงสร้างที่นิยมใช้คือโครงข่ายประสาทเทียมแบบหลายชั้น (Multi-Layer Perceptron: MLP) ซึ่งเป็นโครงสร้างแบบป้อนไปข้างหน้า
โดยตัวอย่างในภาพที่ 2 แสดงถึงโครงสร้างที่ประกอบไปด้วยชั้น (Layer) ต่างๆ 3 ชั้น ได้แก่ ปมขาเข้า (Input Node) คือ ปมที่ให้ข้อมูลจากภายนอกแก่โครงข่ายหรือแบบจำลอง สอดคล้องกับชื่อปมขาเข้า คือ ทำหน้าที่ป้อนข้อมูลให้กับโครงข่ายหรือแบบจำลอง ปมซ่อนเร้น (Hidden Node) คือ ปมที่ไม่มี การเชื่อมต่อไปสู่ภายนอก เป็นปมที่คำนวณและประมวลผลข้อมูลที่ได้รับจากปมขาเข้า แล้วจึงถ่ายเทผลลัพธ์ที่ได้ไปสู่ปมขาออก ซึ่งปมซ่อนเร้นทุกๆปมก็จะอยู่ในชั้นซ่อนเร้นของโครงข่าย และปมขาออก (Output Node) คือ ปมที่แสดงผลลัพธ์หรือผลการคำนวณภายในโครงข่ายที่อยู่ในชั้น ขาออกของโครงข่าย ทั้งนี้ ชั้นซ่อนอาจมีมากกว่าหนึ่งชั้น ในแต่ละชั้นจะประกอบด้วยโหนดหรือเซลล์ประสาทหนึ่งเซลล์หรือมากกว่า และข้อมูลจะถูกส่งจากชั้นข้อมูลเข้า ไปถึงชั้นข้อมูลออกโดยไม่มีการส่งย้อนกลับ แม้โหนดในชั้นเดียวกันก็ไม่มีการเชื่อมต่อกัน
ทั้งนี้ในการนำ ANN ไปใช้นั้น ผู้ใช้จะต้องเลือกจำนวนของชั้นซ่อนและจำนวนปมของแต่ละชั้นซ่อนให้เหมาะสมกับข้อมูล ซึ่งในปัจจุบันยังไม่มีวิธีหรือหลักการที่แน่ชัดในการเลือกจำนวนดังกล่าว ผู้ใช้ ANN อาจต้องใช้วิธีปรับค่าของจำนวนชั้นซ่อนและจำนวนโหนดไปเรื่อยๆ จนกว่าจะพบจำนวนที่เหมาะสม เช่น จำนวนที่ให้ค่าความผิดพลาดน้อยที่สุด แต่ทั้งนี้ก็มีวิธีที่ช่วยในการเลือกโดยที่ผู้ใช้ไม่ต้องปรับแต่งด้วยตนเอง เช่น การใช้ขั้นตอนวิธีทางพันธุกรรม (Genetic อัลกอริทึม) มาช่วยในการหาจำนวนที่เหมาะสม เป็นต้น
ปัจจุบันพบว่า โครงข่ายประสาทเทียม (ANN) ถูกนำมาประยุกต์ใช้อย่างแพร่หลายในการรู้จำแบบ (Pattern Recognition) การจัดหมวดหมู่และแยกแยะ (Clustering and Segmentation) รวมถึงการพยากรณ์ โดยในด้านการพยากรณ์นั้น มักใช้ในกรณีที่ความสัมพันธ์ ระหว่างตัวแปรที่มีความซับซ้อนหรือเป็นแบบไม่เชิงเส้น หรือใช้เป็นอีกหนึ่งทางเลือกในการหาความสัมพันธ์ระหว่างชุดข้อมูลใดหนึ่งๆ ซึ่งไม่มีข้อจำกัดหรือตั้งอยู่บนสมมติฐานใดๆ ที่ไม่สะท้อนความเป็นจริง เช่น ภาวะเชิงเส้น (Linearity) การกระจายตัวแบบปกติ (Normal Distribution) หรือ ความเป็นอิสระซึ่งกันและกันของตัวแปรอิสระ (Independence) และอื่นๆ ซึ่งเป็นข้อจำกัดของการวิเคราะห์โดยเทคนิคทั่วไป นอกจากนี้ การที่โครงข่ายประสาทเทียมสามารถจับรูปแบบความสัมพันธ์ได้หลายรูปแบบทำให้ผู้ใช้สามารถจำลองปรากฏการณ์ได้อย่างรวดเร็วและง่ายดาย ซึ่งอาจเป็นไปได้ยากหรือเป็นไปไม่ได้ถ้าใช้เทคนิคทั่วไป
(2.2) เทคนิคอัลกอริทึม Random Forest
เป็นอัลกอริทึมหนึ่งซึ่งถือว่ามีความแม่นยำสูงมากของ Machine Learning โดย Random Forest ซึ่งมีฐานความคิดจากอัลกอริทึมต้นไม้ตัดสินใจ (Decision Tree) ที่เน้นการสร้างโมเดลด้วยวิธีการสร้างแผนภูมิต้นไม้ (Decision Tree) ขึ้นมาหลายๆ แบบที่ไม่ซ้ำกันโดยวิธีการสุ่มตัวแปร อีกทั้งเพิ่มการสร้างความหลากหลายของโมเดลด้วยการสุ่มแอตทริ-บิวต์ (หรือตัวแปรต้นในทางสถิติ) แล้วนําผลที่ได้แต่ละแผนภูมิต้นไม้ (Decision Tree) มารวมกันพร้อมนับจํานวนรูปแบบของแผนภูมิที่มีจำนวนซ้ำกันมากที่สุด สรุปออกมาเป็นผลลัพธ์สุดท้าย โดยจะเรียกเทคนิควิธีนี้ว่า เทคนิค Ensemble ซึ่งข้อดีของวิธีการนี้คือให้ผลการพยากรณ์ที่แม่นยำและเกิดปัญหา Overfitting[2] น้อย
[2] Overfitting เป็นปัญหาพื้นฐานที่พบบ่อยในการพัฒนาอัลกอรึทิ่ม Machine Learning ทำให้เกิดเหตุการณ์ที่ โมเดลทำงาน (เช่น ทำนายข้อมูล) ได้ดีมากกับ Training Data (in-sample data) แต่ทำงานได้ผิดพลาดเมื่อนำโมเดลนั้นมาทำงานกับ Testing Data (Out-sample Data) ซึ่งเป็นข้อมูลที่โมเดลไม่เคยเห็นมาก่อน
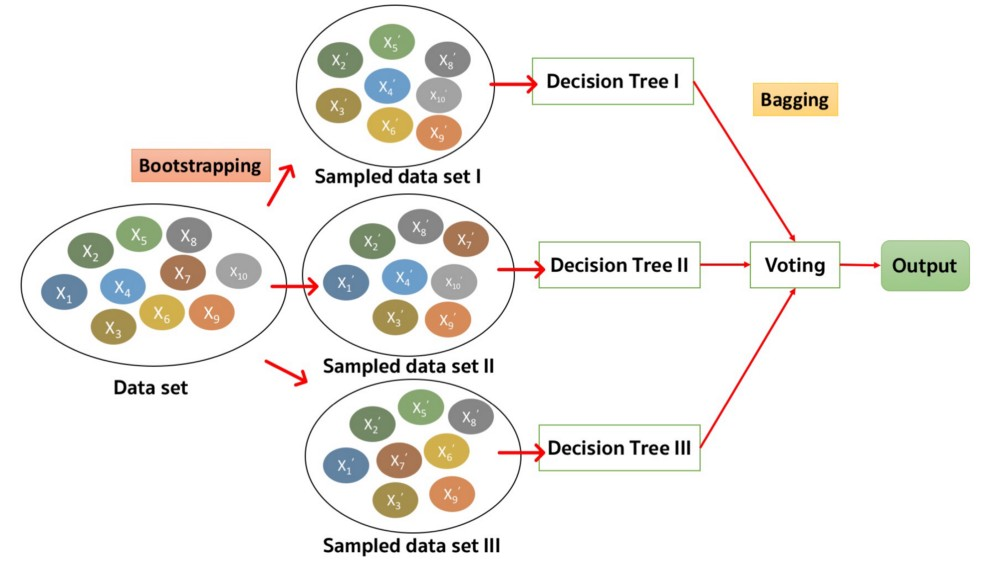
อัลกอริทึม Random Forest จะใช้ตัวแปรทุกตัวในการประมวลผล จะประมวลผลจากสุ่มหาแอตทริบิวต์ (ตัวแปรต้น) ที่สามารถใช้แยกกลุ่มของกลุ่มตัวอย่างออกจากกันหรือการเลือกตัวแปรที่ใช้ในการแบ่งปมการตัดสินใจ (Node) เพื่อสร้างจำนวนข้อมูลในแต่ละกลุ่มที่แบ่งออกมา (Leaf Node) อย่างมีนัยสำคัญได้ ผ่านวิธีการในการแบ่งแยกคัดเลือกตัวแปร คือ การพิจารณาค่า Variable Importance (VIMP) และ ค่า Minimal Depth โดยสามารถสรุปรายละเอียดได้ดังนี้
Variable Importance (VIMP) คือค่าส่วนต่างของค่าความคลาดเคลื่อนของการพยากรณ์ชุดข้อมูลที่แอตทริบิวต์ (ตัวแปรต้น) กับชุดที่แอตทริบิวต์ (ตัวแปรต้น) ถูกสุ่มนำมาใช้ (Breiman, 2001) โดยตัวแปรที่มีค่า VIMP มาก เมื่อมีการสุ่มข้อมูลใหม่จะส่งผลความแปรปรวนของผลลัพธ์มาก กล่าวคือ เมื่อนำตัวแปรไปใส่ในชุดข้อมูล กับกรณีที่ตัวแปรไม่ถูกนำไปใส่ในชุดข้อมูลค่าความคลาดเคลื่อนของผลลัพธ์ต่างกันในระดับสูง สะท้อนถึงความสำคัญของตัวแปรนั้นๆ ที่มีต่อผลลัพธ์การพยากรณ์ สำหรับตัวแปรที่มีค่า VIMP เข้าใกล้ศูนย์และค่าเป็นลบ แสดงถึงคุณลักษณะของตัวแปรดังกล่าวที่ไม่ได้ส่งผลต่อความแปรปรวนของผลลัพธ์ สะท้อนถึงการมีความสำคัญต่ำ (มีตัวแปรนี้หรือไม่ค่าผลลัพธ์ไม่ต่างกันมาก) โดยการนำมาประยุกต์ใช้งาน ควรหลีกเลี่ยงตัวแปรที่มีค่า VIMP ที่เข้าใกล้ศูนย์และค่าเป็นลบ โดยจะเลือกใช้ตัวแปรที่มีค่า VIMP สูง
Minimal Depth ถือว่าเป็นค่าหนึ่งที่ใช้ในการจัดลำดับความสำคัญของ แอตทริบิวต์ (ตัวแปรต้น) โดยแอตทริบิวต์ (ตัวแปรต้น) ที่มีความสำคัญต่อผลลัพธ์การพยากรณ์นั้น จะมีการแบ่งปมอยู่ในลำดับชั้นแรกๆ หรือใกล้เคียงกับราก (Root Node) มากที่สุด โดยแผนภูมิต้นไม้ (Decision Tree) หนึ่งต้นนั้น ระดับตำแหน่งของปม (Node) มีความสัมพันธ์กับระยะทางของลำต้นกับราก (กำหนดให้ราก Root Node คือ 0) โดยค่า Minimal Depth จะสะท้อนความสำคัญของตัวแปร โดยคำนวณค่าเฉลี่ยความลึกของการแบ่งชั้นแรกของแผนภูมิต้นไม้ (Decision Tree) โดยเฉลี่ยทั้งหมดของแผนภูมิต้นไม้ (Decision Tree) ทั้งหมด ทั้งนี้ค่า Minimal Depth น้อยจะแสดงถึงการอยู่ในลำดับชั้นแรกๆ ที่มีความสำคัญอยู่ในระดับสูง ในขณะที่ค่า Minimal Depth มาก จะแสดงถึงการอยู่ในลำดับชั้นหลังๆ มีความสำคัญน้อยในการพยากรณ์ผลลัพธ์ (Ishwaran and Kogalur, 2014)
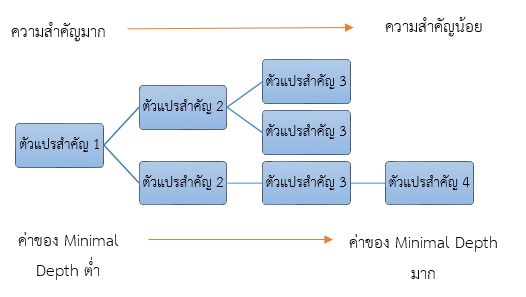
โดยปกติแล้ว Variable Importance (VIMP) จะถูกใช้ในการพิจารณาค่าอย่างไม่มีกฏเกณฑ์ โดยจะมองหาค่าที่สูงจากการจัดลำดับ (Ranking) เพื่อพิจารณาความสำคัญของตัวแปรโดยเบื้องต้นก่อน โดยการวิเคราะห์ว่าตัวแปรใดเมื่อมีการเปลี่ยนแปลงการสุ่มข้อมูลแล้ว จะส่งผลต่อความแปรปรวนของผลลัพธ์ ในขณะที่ Minimal Depth จะเป็นวิธีการเชิงปริมาณที่ใช้ในการสร้างกลุ่มแผนภูมิต้นไม้ (กลุ่มของ Decision Tree ที่มีจำนวนมาก หรือเรียกว่า Forest) โดยตัวแปรที่มีค่า Minimal Depth ต่ำกว่า ค่า Minimal Depth เฉลี่ย จะถือว่าเป็นตัวแปรที่มีความสำคัญสูง และ ตัวแปรที่มีค่า Minimal Depth ต่ำกว่า จะมีความสำคัญมากกว่า
4. วรรณกรรมปริทัศน์
จากการทบทวนวรรณกรรมที่เกี่ยวข้องกับปัจจัยที่มีผลต่อการจ้างงานแรงงาน พบว่างานวิจัยส่วนใหญ่ ปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างของแรงงานนั้น มีการพัฒนามาจากแนวความคิดของ Mincer โดยมีการทำการพิสูจน์และเพิ่มตัวแปรที่หลากหลายมากยิ่งขึ้น ดังเช่นงานศึกษาที่เกี่ยวข้องการรายได้ ค่าตอบแทนของแรงงานจากการศึกษาของ Tangtipongkul (2015), ดวงรัตน์ และคณะ (2555), ปวีณา (2550), เจษฎา และคณะ (2559) และงานของกฤษณะ และ เทอดศักดิ์ (2558) โดยจะพบว่าตัวแปรที่เป็นลักษณะเฉพาะตัวบุคคลนั้น เช่น ตัวแปรจำนวนปีประสบการณ์ ตัวแปรเพศ ตัวแปรสถานภาพ ตัวแปรระดับการศึกษา มีผลต่อความแตกต่างของรายได้ในแต่ละบุคคลเป็นส่วนใหญ่ ในขณะที่ตัวแปรที่เป็นปัจจัยภายนอก เช่น ขนาดกิจการ ตำแหน่งสถานที่ทำงาน จำนวนชั่วโมงการทำงาน ซึ่งก็มีผลต่อความแตกต่างของรายได้ที่แรงงานกำหนดค่าจ้างได้ดังตารางที่ 1
| ปัจจัยกำหนดรายได้/ผู้วิจัย | Mincer (1974) | ปวีณา (2550) | ดวงรัตน์ และคณะ (2555) | Tangtipongkul (2015) | กฤษณะและคณะ (2558) | เจษฎาและคณะ (2559) |
|---|---|---|---|---|---|---|
| ระดับการศึกษา | X | X | ||||
| จำนวนปีการศึกษา | X | X | ||||
| จำนวนปีประสบการณ์ | X | X | X | X | ||
| อายุ | X | |||||
| จำนวนสมาชิกในครอบครัว | X | |||||
| กลุ่มอาชีพ | X | |||||
| เพศ | X | X | X | |||
| สถานภาพ | X | X | X | |||
| ตำแหน่งงาน | X | |||||
| จำนวนวันทำงาน/ ชม. การทำงาน | X | X | ||||
| จำนวนครั้งออกจากงาน | X | |||||
| ตำแหน่งสถานที่ทำงาน | X | X | ||||
| ขนาดกิจการ | X | X |
ที่มา: การรวบรวมโดยผู้วิจัย
จากการศึกษาเอกสารและการศึกษาที่เกี่ยวข้องกับแบบจำลองทางด้านปัญญาประดิษฐ์ พบว่าเทคนิควิธีการทางปัญญาประดิษฐ์ ถูกนำมาใช้ในงานวิจัยต่างๆ รวมถึงงานวิจัยทางด้านทรัพยากรบุคคลมากยิ่งขึ้น โดยจะพบว่าจากงานของ นันทชัย (2555)จะสะท้อนให้เห็นถึงข้อดีและข้อจำกัดของวิธีการทางปัญญาประดิษฐ์ประเภทต่างๆ เมื่อเทียบกับวิธีการทางสถิติ โดยแสดงให้เห็นว่าวิธีการทางปัญญาประดิษฐ์เหมาะสมกับการศึกษาที่มีความซับซ้อนมาก อีกทั้งในส่วนงานวิจัยในระดันนานาชาติ
พบว่าเทคนิควิธีการทางปัญญาประดิษฐ์ โดยเฉพาะอย่างยิ่งเทคนิคโครงข่ายประสาทเทียม (Artificial Neural Networks, ANN) และเทคนิควิธีอัลกอริทึม Random Forest ได้ถูกนำมาใช้ในงานทางด้านทรัพยากรบุคคล เช่น การศึกษาการทำนายศักยภาพพนักงานของ Elamparithi and Kalaivani (2014), Bhulai (2016) และงานเปรียบเทียบประสิทธิภาพของ การสรรหาผู้สมัคร ของ An et al. (2017) ที่นำแบบจำลองทางปัญญาประดิษฐ์ดังกล่าวมาใช้ในการศึกษา และพบว่ามีประสิทธิภาพและความแม่นยำสูงกว่าวิธีการทางสถิติและเศรษฐมิติอื่นๆ นอกจากนี้ จะพบว่าปัจจุบันเริ่มมีการนำเทคนิควิธีการทางปัญญาประดิษฐ์มาใช้ในการศึกษาพยากรณ์ดัชนีค่าจ้าง (Wage Index) ด้วยเช่นกัน อาทิเช่น การศึกษาของ Gert et al. (2019)ซึ่งเป็นการศึกษาการพยากรณ์ดัชนีค่าจ้างโดยใช้ Machine Learningและพบว่า เทคนิควิธี Random Forest นั้น มีค่าความแม่นยำสูงกว่าเทคนิควิธีการทางสถิติ อีกทั้งยังสามารถควบคุม ความผิดพลาดในรูปแบบของ Bias ที่จะเกิดขึ้นจากแบบจำลองทางสถิติได้อีกด้วย
4. วิธีการศึกษา
ผู้วิจัยใช้ข้อมูลการสำรวจภาวะเศรษฐกิจและสังคมของครัวเรือน (Household Socio-Economic Survey: SES) และข้อมูลการสำรวจภาวะการทำงานของประชากร Labor Force Survey: LFS) ระหว่างปี พ.ศ 2550 – 2560 ของสำนักงานสถิติแห่งชาติ ซึ่งข้อมูลดังกล่าวมีการสำรวจและรวบรวมกลุ่มตัวอย่างไว้เป็นจำนวนมากซึ่งเพียงพอในการจะใช้เป็นตัวแทนในการศึกษาปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างในช่วง 10 ปีที่ผ่านมาของหน่วยครัวเรือนและแรงงานทั้งประเทศ โดยเลือกใช้ข้อมูลด้านคุณลักษณะต่างๆ ของประชากรตามที่ได้จากการทบทวนวรรณกรรมมาเป็นตัวแปรที่ใช้ในการศึกษา โดยซึ่งผู้วิจัยได้ดำเนินการแบ่งประเภทของตัวแปรดังกล่าวเป็น 3 กลุ่มประเภทหลัก และปรับปรุงสมการพื้นฐานของ Mincer โดยเพิ่มปัจจัยที่มีอิทธิพลที่ได้จากการทบทวนวรรณกรรม และเพิ่มปัจจัยอื่นๆ ที่น่าจะส่งผลกระทบต่อค่าจ้าง เพื่อนำมาสร้างแบบจำลองพยากรณ์ค่าจ้างแรงงาน โดยแบ่งได้ดังนี้
(1) ปัจจัยด้านคุณลักษณะทั่วไปของแรงงาน เพศ สถานภาพ อายุ จำนวนสมาชิกในครอบครัว ระดับการศึกษา จำนวนปีการศึกษา จำนวนปีประสบการณ์ จำนวนครั้งออกจากงานปัจจัยด้านสายการศึกษา (สายอาชีพ สายสามัญ) สถานะในครอบครัว และสาขาวิชาที่เรียน (สายวิทยาศาสตร์ หรือ สายสังคม)
(2) ปัจจัยที่เกี่ยวข้องกับอาชีพและกิจการ กลุ่มอาชีพ ตำแหน่งงาน จำนวนวันทำงาน ชั่วโมงการทำงาน ขนาดของกิจการ
(3) ปัจจัยทางด้านภูมิศาสตร์ สถานที่ตั้งของกิจการ มาศึกษาถึงความสัมพันธ์กับตัวแปรค่าจ้างที่ได้รับ
จากนั้นจะนำข้อมูลตัวแปรข้างต้นมาศึกษาว่า ปัจจัยใดที่มีอิทธิพลต่อการกำหนดค่าจ้างแรงงานไทยในช่วงปี พ.ศ. 2550 – 2560 และปรับปรุงชุดข้อมูลให้เหลือเพียงแค่ตัวแปรที่มีความสัมพันธ์อย่างมีนัยยะทางสถิติต่อค่าจ้างแรงงานเท่านั้น เพื่อนำมาสร้างแบบจำลองทางเศรษฐมิติ และแบบจำลองทางปัญญาประดิษฐ์ในการพยากรณ์ค่าจ้างแรงงาน (เทคนิควิธีโครงข่ายประสาทเทียม และเทคนิควิธี Random Forest) โดยในขั้นตอนดังกล่าว ใช้โปรแกรมคอมพิวเตอร์ภาษา R ช่วยในการคำนวณ โดยผู้วิจัยแบ่งข้อมูลออกเป็น 2 ชุดหลัก โดยวิธี Split Test[3] ในสัดส่วน 70:30 คือ ข้อมูลที่ใช้ในการเรียนรู้เพื่อสร้างแบบจำลอง (Training Data) ร้อยละ 70 และข้อมูลที่ใช้ทดสอบความถูกต้องของแบบจำลอง (Testing Data) ร้อยละ 30 โดยจะนำข้อมูลไปใส่ในแบบจำลองที่สร้างขึ้น เพื่อพยากรณ์ค่าจ้าง (ตัวแปรชื่อ Approx.) ที่แบบจำลองต่างๆ
[3] วิธี Split Test เป็นการแบ่งข้อมูลด้วยการสุ่มออกเป็น 2 ส่วน เช่น 70% ต่อ 30% หรือ 80% ต่อ 20% ทั้งนี้สัดส่วนการแบ่งขึ้นอยู่กับปริมาณข้อมูลในแต่ละครั้ง โดยปกติมักจะกำหนดให้เป็น 70 : 30
| จำนวนข้อมูล/ปี พ.ศ. | SES 2550 | SES 2552 | SES 2554 | SES 2556 | SES 2558 | LFS 2551 | LFS 2552 | LFS 2553 | LFS 2554 | LFS 2555 | LFS 2556 | LFS 2557 | LFS 2558 | LFS 2559 | LFS 2560 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| observation | 5,102 | 5,096 | 4,575 | 4,564 | 4,371 | 6,193 | 5,464 | 1,217 | 7,590 | 8,147 | 7,964 | 7,782 | 8,011 | 8,304 | 8,224 |
| Training Data | 3,571 | 3,567 | 3,203 | 3,195 | 3,060 | 4,335 | 3,825 | 852 | 5,313 | 5,703 | 5,575 | 5,447 | 5,608 | 5,813 | 5,757 |
| Testing Data | 1,071 | 1,070 | 961 | 958 | 918 | 1,858 | 1,639 | 365 | 2,277 | 2,444 | 2,389 | 2,335 | 2,403 | 2,491 | 2,467 |
ที่มา: จากการรวบรวมของผู้วิจัย
| คุณสมบัติข้อมูล/ปี พ.ศ. | SES 2550 (logarithm) | SES 2552 (logarithm) | SES 2554 (logarithm) | SES 2556 (logarithm) | SES 2558 (logarithm) | LFS 2551 (logarithm) | LFS 2552 (logarithm) | LFS 2553 (logarithm) | LFS 2554 (logarithm) | LFS 2555 (logarithm) | LFS 2556 (logarithm) | LFS 2557 (logarithm) | LFS 2558 (logarithm) | LFS 2559 (logarithm) | LFS 2560 (logarithm) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2550 | 2552 | 2554 | 2556 | 2558 | 2551 | 2552 | 2553 | 2554 | 2555 | 2556 | 2557 | 2558 | 2559 | 2560 | |
| Min | 0.0558 | 0.1193 | 0.1913 | 0.0519 | 0.0918 | 0.2202 | 0.0000 | 0.1582 | 0.1261 | 0.0000 | 0.0000 | 0.4060 | 0.0291 | 0.0389 | 0.0000 |
| Max | 0.9589 | 0.9469 | 1.0000 | 0.9956 | 0.9718 | 0.7724 | 0.9744 | 0.9584 | 0.9017 | 0.9547 | 0.9088 | 0.9313 | 0.9257 | 0.9634 | 0.9597 |
| Mean | 0.7653 | 0.7111 | 0.7118 | 0.7335 | 0.7279 | 0.5168 | 0.5458 | 0.4953 | 0.5193 | 0.4539 | 0.5032 | 0.6319 | 0.4418 | 0.4360 | 0.5083 |
| S.D. | 0.0865 | 0.0868 | 0.0889 | 0.0779 | 0.0917 | 0.0726 | 0.0989 | 0.1104 | 0.0939 | 0.0984 | 0.0792 | 0.0568 | 0.1003 | 0.1023 | 0.0968 |
ในการสร้างแบบจำลองทางเศรษฐมิติที่ใช้พยากรณ์ค่าจ้างแรงงานไทย ผู้วิจัยได้นำสมการกำหนดค่าจ้างของ Mincer (1974) มาพิจารณาและปรับปรุงเพิ่มเติม ดังนี้
WAGEi = α + β0 SEXi + β1AGEi + β2 MARTIALi + β3 RE_EDi + β4 SUBJECTi
+ β5 LINEi + β6 MEMBERi +β7 RELATIONi + β8 INDUSi + β9 OCCUPi
+ β10 MAIN_HRi +β11 SIZEi + β12 REGi + β13 AREAi + εi
โดยรายละเอียดของค่าสัมประสิทธิ์เป็นดังต่อไปนี้
| α | = ค่าคงตัว |
| β0 – β7 | = สัมประสิทธ์ของกลุ่มปัจจัยด้านคุณลักษณะทั่วไปของแรงงาน |
| β8 – β11 | = สัมประสิทธ์ของกลุ่มปัจจัยด้านที่เกี่ยวข้องกับอาชีพและกิจการ |
| β12 – β13 | = สัมประสิทธ์ของกลุ่มปัจจัยด้านภูมิศาสตร์ |
| εi | = ค่าความแปรปรวน |
ทั้งนี้รายละเอียดตัวแปรทั้งหมดในการศึกษานี้ ดังแสดงในตารางที่ 3 ซึ่งประกอบด้วยตัวแปร 3 ประเภท
| ปัจจัยประเภทที่ 1: คุณลักษณะทั่วไปของแรงงาน คุณลักษณะ | ชื่อตัวแปร | ปัจจัยประเภทที่ 2: อาชีพและกิจการ คุณลักษณะ | ชื่อตัวแปร | ปัจจัยประเภทที่ 3: ภูมิศาสตร์ คุณลักษณะ | ชื่อตัวแปร |
|---|---|---|---|---|---|
| เพศ | SEXi | ทักษะอาชีพ | OCCUPi | ภูมิภาค | REGi |
| อายุ | AGEi | จำนวน ชม.ทำงาน | MAIN_HRi | เขตเทศบาล | AREAi |
| สถานภาพสมรส | MARTIALi | ประเภทอุตสาหกรรม | INDUSi | ||
| ระดับชั้นการจบการศึกษา | RE_EDi | ขนาดกิจการ | SIZEi | ||
| สาขาวิชาเรียน | SUBJECTi | ||||
| ประเภทการศึกษา | LINE | ||||
| จน.สมาชิกในครอบครัว | MEMBERi | ||||
| สถานะในครอบครัว | RELATIONi |
ที่มา: การสรุปโดยผู้วิจัย
ในส่วนของแบบจำลองทางปัญญาประดิษฐ์นั้น ผู้วิจัยได้นำชุดข้อมูลที่ผ่านการปรับปรุงข้างต้นมาเพื่อเป็นตัวแปรขาเข้า (Input) และทำการกำหนดรายละเอียดที่เกี่ยวข้องเพื่อใช้ในการสร้างแบบจำลองพยากรณ์ดังต่อไปนี้
แบบจําลองโครงข่ายประสาทเทียม (Artificial Neural Network) ผู้วิจัยกําหนดจำนวนตัวแปรที่เกี่ยวข้องต่างๆ โดยกำหนดให้จํานวนชั้นซ่อนเร้น (Hidden Layer) ในการศึกษาครั้งนี้เท่ากับ 2 โดยจำนวนดังกล่าวสามารถปรับลดเพิ่มเติมได้ โดยพบว่ากรณีเพิ่มค่าสูงขึ้น ระยะเวลาในการประมวลผลจะมากขึ้น แต่จะทำให้ได้ผลการพยากรณ์ที่มีความคลาดเคลื่อนน้อยลง และในส่วนของจํานวนตัวแปรขาออก (Output) นั้น กําหนดให้เป็นอัตราค่าจ้างแรงงานที่อยู่ในรูป Logarithm (ตัวแปรชื่อ APPROX) เพื่อพยากรณ์รายได้ของแรงงานแต่ละคน
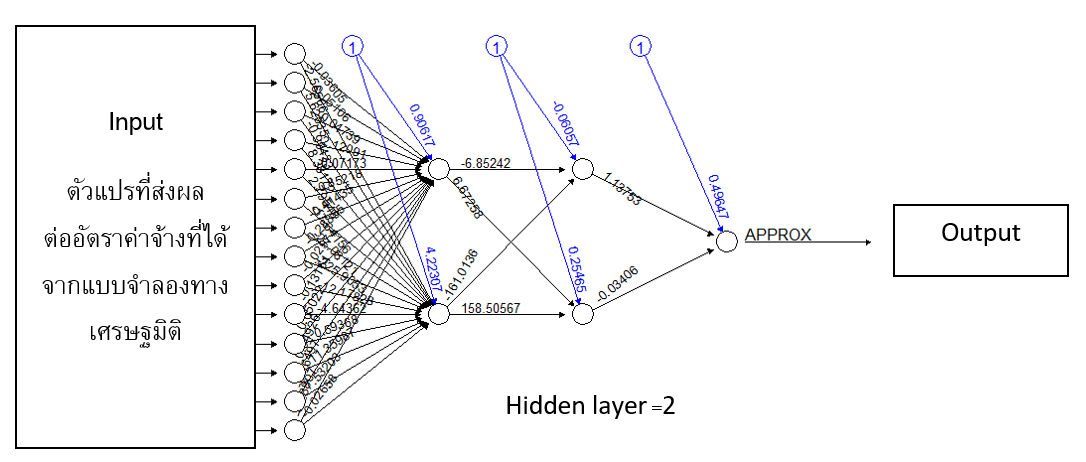
ในส่วนของแบบจําลอง Random Forest ส่วนของกระบวนการ (Process) นั้น ผู้วิจัยกำหนดจำนวนการสร้างแผนภูมิต้นไม้ (Decision Tree) เท่ากับ 1,000 ต้น เพื่อสุ่มตัวอย่างข้อมูลตัวแปรนำเข้าออกมาเป็นตัวอย่าง 1,000 ชุด ที่ไม่หมือนกัน (หรือวิธีการ Bootstrapping) โดยผลลัพธ์ที่ได้ในงานวิจัยนี้ สามารถแบ่งออกเป็น 2 ส่วนหลัก คือ (1) ค่าจ้างแรงงานที่ได้จากการพยากรณ์ของแบบจำลองใน Logarithm (ตัวแปรชื่อ APPROX) ได้มาจากการที่ระบบการคำนวณจะทำการ Aggregation ผลลัพธ์จากแต่ละแผนภูมิต้นไม้ (หรือเรียกว่า Bagging) เพื่อหาค่าเฉลี่ยและนำไปสู่การพยากรณ์ค่าจ้างแรงงานที่แรงงานแต่ละคนได้รับ
(2) การศึกษาปัจจัยที่มีความสำคัญกับค่าจ้างแรงงานของแบบจำลองในแต่ละปี โดยพิจารณา ผ่าน Variable Importance (VIMP) และค่าของ Minimal Depth จากนั้นจะทำการประเมินประสิทธิภาพความแม่นยำของแบบจำลองในการกำหนดราคาค่าจ้าง ทั้งจากวิธีเศรษฐมิติและทางปัญญาประดิษฐ์ด้วยวิธีการต่างๆ เช่น ค่าความคลาดเคลื่อนกำลังสองเฉลี่ย (Mean Squared Error: MSE) และค่า Scatter Plot เพื่อหาวิธีการที่มีประสิทธิภาพสูงสุด
5. ผลการศึกษาและการอภิปรายผล
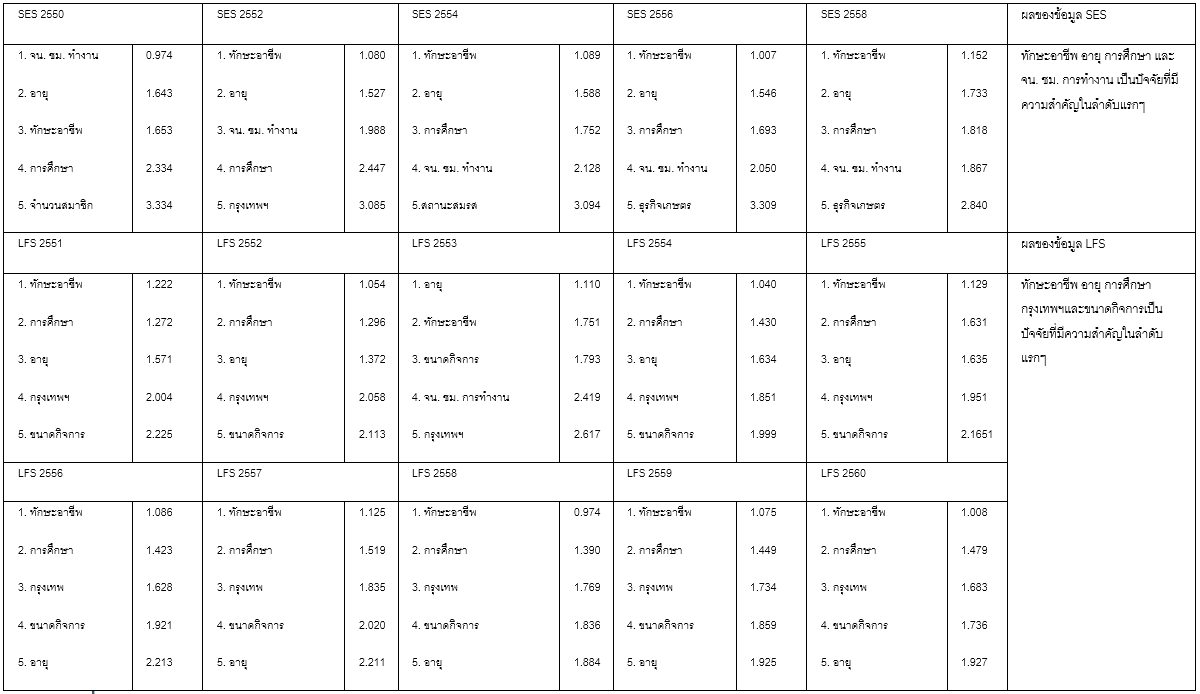
จากผลการศึกษาพบว่า ในช่วงเวลาปี พ.ศ. 2550 – 2560 นั้น ปัจจัยที่มีผลต่อค่าจ้างแรงงานไทยในช่วง 10 ปีที่ผ่านมาจากชุดข้อมูลการสำรวจภาวะเศรษฐกิจและสังคมของครัวเรือน (SES) และข้อมูลการสำรวจภาวะการทำงานของประชากร (LFS) นั้น ผลจากการใช้วิธีการวิเคราะห์ทั้ง 3 แบบจำลอง แสดงให้เห็นถึงตัวแปรที่มีอิทธิพลในแต่ละปีดังต่อแสดงในตารางที่ 4
ที่มา: การสรุปผลการคำนวณโดยผู้วิจัย
ทั้งนี้สามารถสรุปภาพรวมปัจจัยที่มีอิทธิพลต่อการกำหนดค่าจ้างแรงงานในช่วง
พ.ศ. 2550 – 2560 ได้ดังนี้
(1) ปัจจัยด้านคุณลักษณะทั่วไปของแรงงาน พบว่าตัวแปรเพศชาย (SEX) อายุ (AGE) ระดับชั้นการจบการศึกษา (RE_ED) เป็นตัวแปรที่มีอิทธิพลต่อค่าจ้างแรงงานอย่างมีนัยสำคัญในทุกปี และทุกชุดข้อมูล ซึ่งสะท้อนให้เห็นว่าในกรณีที่การศึกษาของแรงงานเพิ่มสูงขึ้น หรืออายุของแรงงาน เพิ่มขึ้น สะท้อนถึงประสบการณ์ทำงานที่เพิ่มขึ้น จะส่งผลต่อค่าจ้างแรงงานที่สูงขึ้นในทิศทางเดียวกัน ในขณะที่เรื่องเพศยังคงมีผลต่อค่าจ้าง ซึ่งสะท้อนถึงความเหลื่อมล้ำทางเพศที่ส่งผลต่อรายได้ ซึ่งถือว่าเป็นปัญหาที่ควรจับตามองและศึกษาต่อไป ในขณะที่ตัวแปรสถานภาพสมรส (MARITAL) และสาขาวิชาวิทยาศาสตร์ (SUBJECT) เป็นตัวแปรที่มีผลต่อค่าจ้างแรงงานโดยส่วนใหญ่
(2) ปัจจัยที่เกี่ยวข้องกับอาชีพและกิจการ พบว่าตัวแปรทักษะอาชีพ (OCCUP) และประเภทอุตสาหกรรม เป็นตัวแปรที่มีอิทธิพลต่อค่าจ้างแรงงานอย่างมีนัยสำคัญในทุกปีและทุกชุดข้อมูล และตัวแปร โดยเฉพาะอุตสาหกรรมด้านการเงินและประกันภัย (INDUS3) ซึ่งสะท้อนให้เห็นว่าหากแรงงานประกอบอาชีพที่แตกต่างกัน โดยเป็นลักษณะอาชีพที่เน้นการใช้ความคิดและการปรับตัวตามสถานการณ์มากขึ้น ใช้ทักษะการทำงานที่สูงขึ้น ย่อมส่งผลต่อรายได้ที่เพิ่มสูงขึ้น อีกด้วย ซึ่งแต่ละอุตสาหกรรมต่างก็มีการจ่ายค่าจ้างที่แตกต่างกันออกไป อีกทั้งตัวแปร จำนวนชั่วโมงการทำงาน (MAIN_HR) ยังมีผลต่อค่าจ้างแรงงานโดยส่วนใหญ่
(3) ปัจจัยทางภูมิศาสตร์ พบว่าตัวแปรด้านสถานที่ทำงานในกรุงเทพ และภาคกลางมีผลต่อค่าจ้างแรงงานอย่างมีนัยสำคัญ ในทุกปีและทุกชุดข้อมูล สะท้อนถึงความเหลื่อมล้ำระหว่างแรงงานในกรุงเทพ ภาคกลางที่แตกต่างจากภูมิภาคอื่นอย่างเห็นได้ชัด และตัวแปรเขตเทศบาล (AREA) ยังมีผลต่อค่าจ้างแรงงานเมื่อเทียบกับพื้นที่นอกเขตเทศบาลโดยส่วนใหญ่
นอกจากนี้ เมื่อนำตัวแปรที่มีอิทธิพลต่อค่าจ้างแรงงานไปดำเนินการสร้างแบบจำลองโดยวิธีการทางเศรษฐมิติ (LM) และแบบจำลองทางปัญญาประดิษฐ์ ทั้งแนวคิดวิธีโครงข่ายประสาทเทียม (ANN) และวิธี Random Forest นั้น ผลการศึกษาประสิทธิภาพและความแม่นยำในการพยากรณ์ดังนี้
(1) เมื่อพิจารณาจากค่าความคลาดเคลื่อนกำลังสองเฉลี่ย (MSE.RF) โดยการเปรียบเทียบค่าพยากรณ์ที่คำนวณได้จากวิธีที่เลือกมา กับค่าข้อมูลจริง ณ ช่วงเวลานั้นๆ ว่าแตกต่างกันมากน้อยเพียงใด โดยค่า MSE มีค่าน้อย ยิ่งสะท้อนถึงความคลาดเคลื่อนที่น้อย แบบจำลองมีประสิทธิภาพสูง โดยภาพที่ 6และ 7 แสดงให้เห็นว่าแบบจำลองวิธีการปัญญาประดิษฐ์นั้นมีประสิทธิภาพมากกว่าวิธีการทางสถิติ โดยสามารถวัดได้จากค่าความคลาดเคลื่อนกำลังสองเฉลี่ย (MSE.RF) ที่ต่ำกว่าแบบจำลองทางเศรษฐมิติ (LM) ในขณะที่เมื่อเทียบกับแบบจำลองทางปัญญาประดิษฐ์ด้วยกัน จะพบว่า วิธีการ Random Forest นั้นมีประสิทธิภาพสูงกว่าวิธีการโครงข่ายประสาทเทียม (ANN) และมีค่าความคลาดเคลื่อนกำลังสองเฉลี่ย (MSE.RF) ที่ต่ำที่สุด
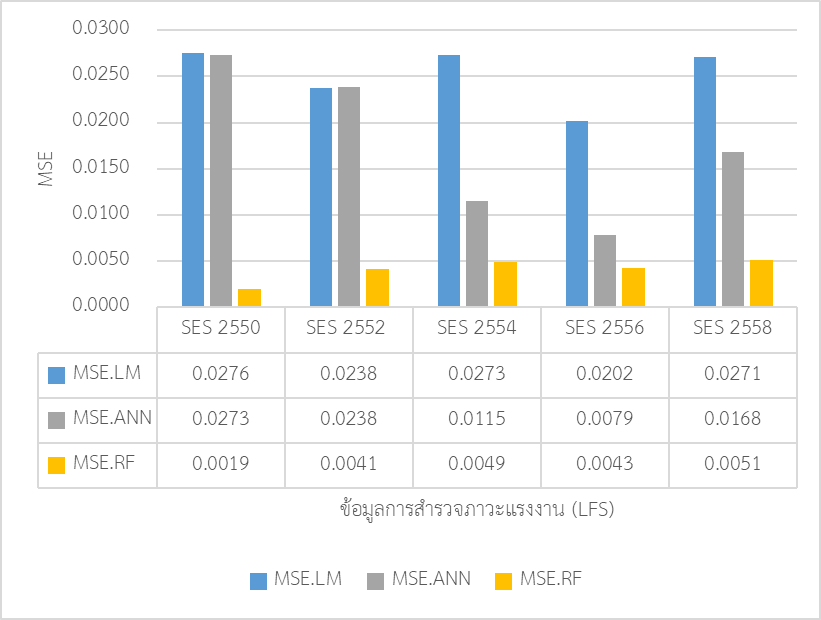
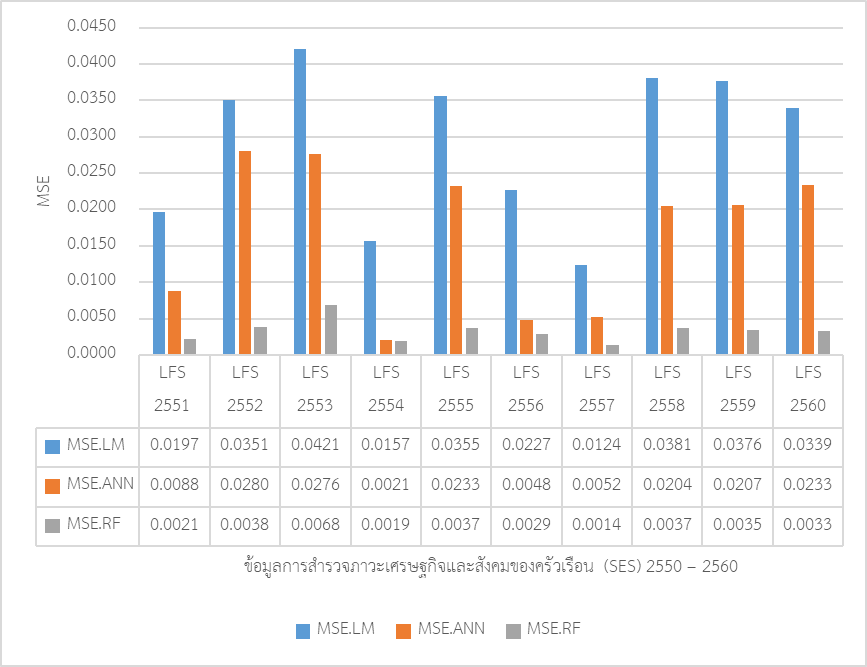
(2) เมื่อพิจารณาผลจากแผนภาพแบบ Scatter Plot ที่แสดงถึงค่าตัวแปรตาม (ค่าจ้างแรงงาน) ที่ได้จากแบบจำลอง (ค่าในแกนตั้ง) โดยเปรียบเทียบกับค่าจริงจากกลุ่มข้อมูลที่ใช้ทดสอบความถูกต้องของแบบจำลอง (Testing Data) (ค่าในแกนแนวราบ) (ดังแสดงในภาพที่ 8) ซึ่งหากค่าที่ได้จากแบบจำลองมีความใกล้เคียงกับค่าที่เกิดขึ้นจริง ตำแหน่งบนจุดของภาพจะต้องมีความใกล้หรือทับกับเส้นเฉียงทำมุม 45 องศากับแนวแกนราบ (แนวเส้นทแยงมุมจากมุมซ้ายล่างไปมุมบนขวา) ซึ่งจะพบว่าตำแหน่งของจุดสีแดงซึ่งเป็นผลจากวิธีการ Random Forest มีความกระจุกตัวอยู่ในแนวเส้นทแยงมุมดังกล่าว ซึ่งสะท้อนว่าค่าของตัวแปรที่ได้จากการการพยากรณ์ของแบบจำลองกับค่าที่เป็นค่าจริงของข้อมูลตัวอย่างมีความใกล้เคียงกันในระดับสูง
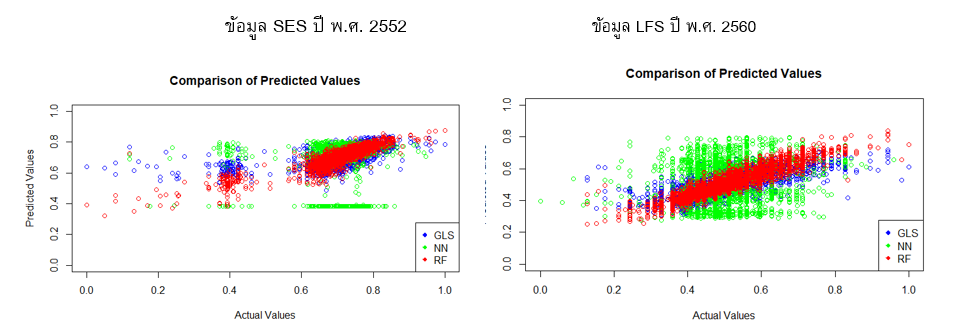
ในขณะข้อมูลตำแหน่งจุดสีเขียวที่เป็นผลของแบบจำลองทางเศรษฐมิติและแบบจำลองโครงข่ายประสาทเทียม (ANN) ไม่อยู่ในแนวทแยงมุมมากนัก นอกจากนี้ ในบางปีมีตำแหน่งการกระจายตัวที่ค่อนข้างเป็นเส้นตรงขนานกับแนวนอน ซึ่งพบว่าเป็นผลเนื่องจากข้อจำกัดของวิธีการในการจัดการคำนวนกับชุดของข้อมูลที่มีลักษณะเป็นตัวแปรแบบ Discrete จำนวนมาก ทำให้การประมวลผลอาจจะผิดพลาดมากขึ้น
นอกจากผลลัพธ์ของการพยากรณ์มูลค่าของค่าจ้างแล้ว วิธีการ Random Forest ยังสามารถแสดงผลของการวิเคราะห์ Variable Importance (VIMP) ซึ่งจะแสดงว่าตัวแปรแต่ละตัวสามารถอธิบายความแปรปรวนของตัวแปรรายได้ ได้เป็นสัดส่วนเท่าใด โดยค่ายิ่งสูงจะยิ่งสะท้อนถึงความสำคัญของตัวแปรนั้นๆ ที่มีต่อค่าจ้าง
| SES 2550 | SES 2552 | SES 2554 | SES 2556 | SES 2558 | ผลของข้อมูล SES |
|---|---|---|---|---|---|
| 1. จน. ชม.การทำงาน 2. อายุ 3. ทักษะอาชีพ 4. การศึกษา 5. เพศ | 1. ทักษะอาชีพ 2. อายุ 3. เพศ 4. จน. ชม.การทำงาน 5. การศึกษา | 1. ทักษะอาชีพ 2. อายุ 3. การศึกษา 4. จน. ชม.การทำงาน 5. เพศ | 1. อายุ 2. ทักษะอาชีพ 3. จน. ชม.การทำงาน 4. เพศ 5. การศึกษา | 1. ทักษะอาชีพ 2. อายุ 3. จน. ชม.การทำงาน 4. เพศ 5. การศึกษา | จำนวนชั่วโมงการทำงาน อายุ ทักษะอาชีพ การศึกษา และเพศ เป็นปัจจัยที่มีผลต่อความแปรปรวนของค่าจ้างแรงงาน |
| LFS 2551 | LFS 2552 | LFS 2553 | LFS 2554 | LFS 2555 | ผลของข้อมูล LFS |
| 1. การศึกษา 2. อายุ 3. ทักษะอาชีพ 4. กรุงเทพฯ 5. ขนาดของกิจการ | 1. อายุ 2. การศึกษา 3. ทักษะอาชีพ 4. กรุงเทพฯ 5. เพศ | 1. อายุ 2. การศึกษา 3. ทักษะอาชีพ 4. ขนาดกิจการ 5. กรุงเทพฯ | 1. ทักษะอาชีพ 2. อายุ 3. การศึกษา 4. ขนาดกิจการ 5. กรุงเทพฯ | 1. อายุ 2. ทักษะอาชีพ 3. การศึกษา 4. ขนาดกิจการ 5. กรุงเทพฯ | การศึกษา อายุ ทักษะอาชีพ กรุงเทพฯ และขนาดกิจการ เป็นปัจจัยที่มีผลต่อความแปรปรวนของค่าจ้างแรงงาน |
| LFS 2556 | LFS 2557 | LFS 2558 | LFS 2559 | LFS 2560 | |
| 1. อายุ 2. การศึกษา 3. ทักษะอาชีพ 4. ขนาดกิจการ 5. กรุงเทพฯ | 1. การศึกษา 2. ทักษะอาชีพ 3. อายุ 4.การศึกษาสายสามัญ 5. ขนาดกิจการ | 1. อายุ 2. ขนาดกิจการ 3. ทักษะอาชีพ 4. เพศ 5. กรุงเทพฯ | 1. การศึกษา 2. ทักษะอาชีพ 3. อายุ 4. ขนาดกิจการ 5. กรุงเทพฯ | 1. ทักษะอาชีพ 2. การศึกษา 3. อายุ 4. ขนาดกิจการ 5. กรุงเทพฯ |
ที่มา: จากการรวบรวมของผู้วิจัย
ที่มา: จากการรวบรวมของผู้วิจัย
นอกจากนี้ วิธีการ Random Forest ยังสามารถใช้แสดงลำดับความสำคัญของตัวแปร ผ่านการคำนวณค่าของ Minimal Depth (ดังแสดงในตารางที่ 5) ซึ่งจะใช้ระบุว่าตัวแปรแต่ละตัวโดยเฉลี่ยแล้วอยู่ที่ลำดับชั้นใดในแผนภูมิต้นไม้ (Decision Tree) ที่ถูกสร้างขึ้นเพื่อวิเคราะห์ความสัมพันธ์กับตัวแปรรายได้ โดยถ้าค่าต่ำแสดงว่าตัวแปรนั้นอยู่ลำดับชั้นบน หรือก็คือตัวแปรลำดับแรกๆ ที่ต้องนำมาใช้พิจารณาก่อน ซึ่งทั้งการวิเคราะห์ VIMP และ Minimal Depth เป็นจุดแข็งอีกประการของวิธีการ Random Forest นอกจากการใช้ในการพยากรณ์ ซึ่งวิธีการอื่น เช่น โครงข่ายประสาทเทียม (ANN) ไม่สามารถแสดงผลการวิเคราะห์ในลักษณะนี้ได้
6. บทสรุป
จากผลการศึกษาพบว่า ในช่วงเวลาปี พ.ศ. 2550 – 2560 นั้น ตัวแปรที่มีอิทธิพลในการกำหนดค่าจ้างแรงงานคือ (1) ปัจจัยด้านคุณลักษณะทั่วไปของแรงงาน พบว่าตัวแปรเพศชาย (SEX) อายุ (AGE) ระดับชั้นการจบการศึกษา (RE_ED) เป็นตัวแปรที่มีอิทธิพลต่อค่าจ้างแรงงานอย่างมีนัยสำคัญในทุกปี (2) ปัจจัยที่เกี่ยวข้องกับอาชีพและกิจการ พบว่าตัวแปรทักษะอาชีพ (OCCUP) และประเภทอุตสาหกรรม เป็นตัวแปรที่มีอิทธิพลต่อค่าจ้างแรงงานอย่างมีนัยสำคัญในทุกปีและทุกชุดข้อมูล และ (3) ปัจจัยทางภูมิศาสตร์ ภูมิศาสตร์ พบว่าตัวแปรด้านสถานที่ทำงานในกรุงเทพ และภาคกลางมีผลต่อค่าจ้างแรงงานอย่างมีนัยสำคัญในทุกปี และทุกชุดข้อมูล
นอกจากนี้ เมื่อนำตัวแปรที่มีอิทธิพลต่อค่าจ้างแรงงานไปดำเนินการสร้างแบบจำลองโดยวิธีการทางเศรษฐมิติ (สมการถดถอยเชิงเส้น หรือ LM) และแบบจำลองทางปัญญาประดิษฐ์ (วิธีโครงข่ายประสาทเทียม (ANN) และวิธี Random Forest) พบว่าแบบจำลองวิธีการปัญญาประดิษฐ์นั้น มีประสิทธิภาพมากกว่าวิธีการทางเศรษฐมิติ ในขณะเดียวกันเมื่อเทียบกับแบบจำลองทางปัญญาประดิษฐ์ด้วยกัน จะพบว่าวิธีการ Random Forest นั้น มีประสิทธิภาพสูงกว่า และยังสามารถให้ผลลัพธ์ที่นอกเหนือจากการพยากรณ์ค่าจ้างของแรงงาน โดยสามารถอธิบายรายละเอียดของความสัมพันธ์ทั้งในด้านการอธิบายลำดับความสัมพันธ์ของแต่ละตัวแปรที่ส่งผลต่อความแปรปรวนของตัวแปรรายได้ (หรือการวิเคราะห์ Variable Importance: VIMP) อีกทั้งยังสามารถใช้แสดงความสำคัญของตัวแปร (ซึ่งแสดงโดยการวิเคราะห์ค่า Minimal Depth) ในขณะที่วิธีการโครงข่ายประสาทเทียม (ANN) ทำได้แค่เพียงพยากรณ์ค่าจ้าง อีกทั้งยังพบข้อจำกัดของผลการพยากรณ์ในกรณีที่มีตัวแปรแบบ Discrete จำนวนมาก โดยจากการวิเคราะห์ในงานวิจัยนี้สามารถสรุปผลประสิทธิภาพของแบบจำลองได้ดังแสดงในตารางที่ 7
| คุณลักษณะประสิทธิภาพ | แบบจำลองทางเศรษฐมิติ (LM) | แบบจำลองทางปัญญาประดิษฐ์ ANN | แบบจำลองทางปัญญาประดิษฐ์ Random Forest (RF) |
|---|---|---|---|
| ประสิทฺธิภาพการทำนาย | ประสิทธิภาพ การทำนายต่ำที่สุด | ประสิทธิภาพ การทำนายต่ำกว่า RF | ประสิทธิภาพ การทำนายสูงที่สุด |
| ค่า Scatter plot | กระจายตัวสูงสุด | กระจุกตัวและบางส่วนกระจายตัวเป็นเส้นตรง เนื่องจากข้อจำกัดของ ANN ที่มีต่อตัวแปร แบบ discrete | กระจุกตัวสูงสุดตามแนวเส้นทแยงมุม 45 องศา |
ที่มา: จากการรวบรวมโดยผู้วิจัย
7. ข้อเสนอแนะ
เนื่องจากเทคนิควิธีทางปัญญาประดิษฐ์ มีเทคนิควิธีการที่มีความหลากหลาย และมีความแม่นยำสูงเฉกเช่นเดียวกับแบบจำลองที่ได้นำมาใช้การวิจัยครั้งนี้ เพื่อต่อยอดการศึกษาต่อไปนั้น สามารถศึกษาเพิ่มเติมได้โดย
(1) ผู้วิจัยสามารถนำเทคนิควิธีการ Machine Learning ที่เป็นอัลกอริทึมอื่นๆ ที่สามารถอธิบายได้ถึงความสัมพันธ์ และอิทธิพลของปัจจัยที่ส่งผลต่อค่าจ้างเงินเดือน ที่มีความแม่นยำมาใช้ในการวิเคราะห์ต่อไป เช่น อัลกอริทึม Support Vector Regression เพื่อให้มีการเปรียบเทียบที่หลากหลายมากขึ้น
(2) ในการศึกษาต่อไป อาจจะทำการทดสอบ Robustness Check ของค่าระดับความแม่นยำของแต่ละอัลกอริทึม โดยการปรับสัดส่วน Training Data และ Testing Data จาก 70:30 เป็น 50:50 หรือ 40:60 เพื่อหลีกเลี่ยงปัญหา Overfitting และเพื่อให้แน่ใจอัลกอริทึมที่ถูกเทรนแล้วสามารถนำไปใช้พยากรณ์กับข้อมูล Out of Sample หรือข้อมูลที่เกี่ยวข้องแม่นยำมากขึ้น
(3) ผู้วิจัยสามารถเพิ่มปัจจัยที่คาดว่าจะมีผลต่อค่าจ้างเงินเดือนของไทย เพื่อศึกษาเชิงลึกมากยิ่งขึ้น เพื่อให้สามารถนำไปใช้ในการในการวางแผนในการพัฒนาแรงงานไทย ให้สามารถพัฒนาทักษะที่เหมาะสมสำหรับ Thailand 4.0 และเตรียมความพร้อมเข้าสู่สังคมผู้สูงวัยที่กำลังจะเกิดขึ้น
(4) ผู้วิจัยสามารถนำเทคนิควิธีการทางปัญญาประดิษฐ์ในงานศึกษานี้ ไปใช้กับงานศึกษาทางด้านทรัพยากรมนุษย์ใหม่ๆ ต่อไป อาทิเช่น
(4.1) ด้านการสรรหาพนักงาน (Recruitment) ใช้ในการทำนายพยากรณ์การคัดเลือกพนักงานของแผนกหรือส่วนงานต่างๆ ผ่านการศึกษาลักษณะของพนักงานในองค์กร เพื่อพยากรณ์บุคคลที่มีแนวโน้มถูกจ้างงาน ตลอดจนการศึกษาด้านค่าตอบแทนขององค์กรเมื่อเทียบกับตลาดภายนอก
(4.2) ด้านการรักษาพนักงาน (Retention) การนำไปใช้ในการพยากรณ์บุคคลที่มีแนวโน้มจะลาออกจากองค์กร หรือการพยากรณ์เรื่องความก้าวหน้า การวางแผนอาชีพของพนักงาน เช่นการศึกษาแนวทาง รูปแบบการหมุนเวียนของพนักงานภายในองค์กร
(4.3) ด้านการพัฒนาพนักงาน (Training) การนำไปใช้ด้านการศึกษารูปแบบการเรียนรู้ของพนักงาน เพื่อวางแผนการฝึกอบรมของพนักงานภายในองค์กร
8. ข้อจำกัดในการศึกษา
(1) การศึกษาครั้งนี้เป็นการศึกษาจาก 2 ชุดข้อมูล ประกอบด้วยข้อมูลการสำรวจภาวะเศรษฐกิจและสังคมของครัวเรือน (SES) และข้อมูลการสำรวจภาวะการทำงานของประชากร (LFS) ทำให้ข้อมูลดิบมีความแตกต่างกัน และต้องเลือกนำมาใช้อย่างระมัดระวัง โดยจะต้องพิจารณารายละเอียดของแบบสอบถามและโครงสร้างข้อมูล (Data Dictionary) อย่างถี่ถ้วน และเลือกนำมาใช้เพื่อให้การประมวลผลไปในทิศทางเดียวกัน ซึ่งจะพบว่าชุดข้อมูลที่ศึกษา อีกทั้งในเรื่องของความสมบูรณ์ของข้อมูลที่ได้จากการเก็บนั้นอาจไม่ครบถ้วน ทำให้ต้องตัดส่วนที่ไม่สมบูรณ์ก่อนนำมาใช้ และส่งผลให้จำนวนข้อมูลในบางปีอาจจะมีไม่เท่ากัน
(2) การศึกษาครั้งนี้ศึกษาในปัจจัยที่เป็นปัจจัยพื้นฐานทั่วไป ทำให้ไม่อาจครอบคลุมปัจจัยกรณีที่เกิดเหตุการณ์ที่แตกต่างไม่จากปกติ เช่น นโยบายรัฐบาลในการปรับอัตราเงินเดือนขั้นต่ำ หรือสถานการณ์ทางเศรษฐกิจต่างๆ อีกทั้งผลการพยากรณ์เป็นผลในการทำนายค่าจ้างในช่วงเวลาหนึ่งเท่านั้น ซึ่งอาจไม่สามารถนำแบบจำลองไปใช้อ้างอิงกับทุกๆ ช่วงเวลาได้
(3) ในการศึกษาครั้งนี้ พบว่าแบบจำลองโครงข่ายประสาทเทียม (ANN) มีข้อจำกัดในเรื่องของการประมวลผลข้อมูลที่ประกอบไปด้วยตัวแปรในลักษณะ Discrete จำนวนมาก ส่งผลให้ต้องมีการปรับการศึกษาโดยทำการหาปัจจัยที่มีอิทธิพลต่อค่าจ้างเงินเดือนโดยเบื้องต้น เพื่อปรับลด ข้อมูลดิบให้เหลือเพียงแต่ตัวแปรที่มีความสัมพันธ์ เพื่อลดจำนวนตัวแปรนำเข้าที่เป็นตัวแปรลักษณะ Discrete ทำให้แบบจำลองสามารถประมวลผลได้ดีขึ้น ดังนั้น ในการศึกษาครั้งต่อไป อาจจะต้องทำการเลือกวิธีการศึกษาที่เหมาะสมกับลักษณะของข้อมูลมากยิ่งขึ้น เนื่องจากอัลกอริทึม Machine Learning แต่ละอัลกอริทึมจะมีขีดความสามารถและข้อจำกัดแตกต่างกันไป โดยจะต้องพิจารณาความสมดุลกันระหว่างความสามารถในการอธิบายผลและความแม่นยำ เพื่อให้งานศึกษาครั้งต่อไปมีความครบถ้วนมากยิ่งขึ้น
รายการอ้างอิง
กฤษณะ เลิศเกษตรวิทยา, เทอดศักดิ์ ชมโต๊ะสุวรรณ, (2558). การวิเคราะห์ปัจจัยที่ส่งผลต่อความแตกต่างทางด้านรายได้ในกำลังแรงงานไทย, เอกสารสืบเนื่องจากการประชุมวิชาการระดับชาติ ครั้งที่ 3, วิทยาลัยนวัตกรรมสังคม มหาวิทยาลัยรังสิต, ปทุมธานี, ประเทศไทย.
จิรพล ภูมิภักดี. (2546). การศึกษาความต้องการแรงงานต่างด้าวของผู้ประกอบการในจังหวัดกาญจนบุรี. (ภาคนิพนธ์). บริหารธุรกิจมหาบัณฑิต สถาบันราชภัฏสวนดุสิต.
เจษฎา นกน้อย. (2550) การจัดการผู้มีความสามารถสูง : ปัจจัยสำคัญสู่ความได้เปรียบทางการแข่งขันขององค์การ. Chulalongkorn Review. 19(74) : 43-57.
เจษฎา นกน้อย, วรรณภรณ์ บริพันธ์, กัญญภัทธ บูหมัด, และ สาทินี สุวิทย์พันธุ์วงศ์. (2559). ปัจจัยที่ส่งผลต่อ ค่าจ้างแรงงานต่างด้าวในอุตสาหกรรมรับเหมาก่อสร้างจังหวัดสงขลา. (รายงานการวิจัยฉบับสมบูรณ์). มหาวิทยาลัยทักษิณ, คณะเศรษฐศาสตร์และบริหารธุรกิจ.
นพดล บูรณะธนัง พรเกียรติ ยั่งยืน และ โสมสิริ หมัดอะดั้ม. (2559). พฤติกรรมการกําหนดค่าจ้างของไทย. โครงการศึกษาด้านโครงสร้างเศรษฐกิจไทยที่มีนัยต่อการดำเนินนโยบาย ธนาคารแห่งประเทศไทย.
นันทชัย กานตานันทะ, (2555). การพยากรณ์ด้วยวิธีการพยากรณ์เชิงสาเหตุ. วารสารวิศวกรรมศาสตร์, 35-48.
ดวงรัตน์ ถนอมพวก, มนต์ชัย พินิจจิตรสมุทธ, และ กุลภา กุลดิลก. (2555). ทุนมนุษย์กับรายได้จากการเกษตร. (รายงานการวิจัยฉบับสมบูรณ์). มหาวิทยาลัยขอนแก่น, คณะเศรษฐศาสตร์.
ปวีณา ลี้ตระกูล, (2557). ปัจจัยที่มีผลต่อความแตกต่างของค่าจ้างระหว่างผู้หญิงและผู้ชายในตลาดแรงงานของไทย. วารสารเศรษฐศาสตร์และนโยบายสาธารณะ, 38-54.
เสาวณี จันทะพงษ์ และ ปาณิศาร์ เจษฎาอรรถพล. (2558). อะไรเป็นปัจจัยกำหนดค่าจ้างของผู้ประกอบการไทย? แจงสี่เบี้ย : รวมคอลัมนิสต์ด้านเศรษฐกิจ การเงิน จากแบงก์ชาติ.
เสาวณี จันทะพงษ์ และกรวิทย์ ดันศรี. (2554). การขาดแคลนแรงงานไทย: สภาพปัญหา สาเหตุและแนวทางแก้ไข. สืบค้นจาก http://www.bot.or.th/Thai/EconomicConditions/Semina/Monthly Workshop/Documents/Labour Shortage.pdf
เอกสิทธิ์ พัชรวงศ์ศักดา, (2557). การวิเคราะห์ข้อมูลด้วยเทคนิคดาต้า ไมน์นิง เบื้องต้น. กรุงเทพ: บริษัท เอเชีย ดิจิตอลการพิมพ์ จำกัด.
Mincer, J. (1974). Schooling, Experience and Earnings. New York: National Bureau of Economic Research.
Bhulai, D. S. (2016). Analysing Which Factors Are of Influence in Predicting. Research Paper Business Analytics Vrije Universiteit Amsterdam.
Breiman L. (2001). Random Forests. Machine Learning, 45(1), 5–32.
Changki, L. & Gary, G. L., (2006). Information Gain and Divergence – base Feature Selection for Machine Learning-based Text Categorization. Journal of Information Processing and Management, 42(1), 155-165.
Gareth J., Daniela W., Trevor H. & Robert T. (2015). An Introduction to Statistical Learning with Applications in R. London: Springer New York Heidelberg Dordrecht.
Gert, B., Shyngys, K. & Jozef, K. (2019). Wage Indexation and Jobs: a Machine Learning Approach. Research Center of Economic: VIVES DISCUSSION PAPER.
Howard, J. (2018). Machine Learning for Coders. Retrieved from course.fast.ai: http://course.fast.ai/ml.html
Irwin, G.W., Warwick, K., & Hunt, K. J. (1995). Neural Network Applications in Control. Short Run Press Ltd., England.
Ishwaran, H. & Kogalur U.B. (2014). Random Forests for Survival, Regression and Classification (RF-SRC), R package version 1.6., URL http://CRAN.R-project.org/package=randomForestSRC.
Jeronepol, S. (2014). ระบบเศรษฐกิจในโลกปัจจุบัน. Retrieved from http://somchai4359.blogspot.com/
Mijwel, M. M. (2018). Artificial Neural Networks Advantages and Disadvantages. Retrieved from researchgate: https://www.researchgate.net/publication/323665827
Elamparithi, V. (2014). An Efficient Classification Algorithms for Employee. International Journal of Research in Advent Technology, 2(9), 29-32.
Pham, H. T. & Reilly, B. (2007). The Gender Pay Gap in Vietnam, 1993-2002; A Quantile Regression Approach. Journal of Asian Economics 18: 775-808
Quadri, M.& Kalyankar, D.N.V. (2010). Drop Out Feature of Student Data for
Academic Performance Using Decision Tree Techniques. Global Journal of
Computer Science and Technology 10(2), 2-5.
Sebastian, R. (2015). Python Machine Learning. Birmingham,UK: Packt Pulishing.
Tangtipongkul, K., (2015). Rates of Return to Schooling in Thailand. Asian Development Review, 32(2), 38-64,
Kalaivani, M.V. (2014). An Efficient Classification Algorithms for Employee. International Journal of Research in Advent Technology, 2(9), 29-32.
An, Z.Y., Shen, H.F. & Wang, S.T. (2017). Employee Recruitment Method Based on Random Forest . 2017 5th International Conference on Computer, Automation and Power Electronics (CAPE 2017), 182-186.



ผศ.ดร.มณเฑียร สติมานนท์
ผู้เขียน
