
By
Nami Hama
Roy Melville
Introduction
In today’s financial landscape, credit scoring models have gained significant importance as tools for assessing a loan applicant’s creditworthiness. These models evaluate the probability of default based on historical performance data (Vidal & Barbon, 2019). Scoring models are used for many purposes but are not limited to reducing the time needed in the loan approval process and improving objectivity and accuracy (Mester, 1997). Credit scoring models can be developed using various methodologies, from traditional statistical techniques to modern machine-learning approaches. This paper will concentrate on the statistical method of logistic regression. It will first introduce the logistic regression model, the dataset and relevant variables, then detail the logistic regression methodology and apply this approach to Thai SMEs. Additionally, it will review existing literature to recommend non-financial data as alternatives when performance data is scarce.
Logistic regression model
This paper will focus on developing a credit scoring model using logistic regression. While other methods, such as decision trees, are available, logistic regression is often preferred for several reasons (Altman & Sabato, 2005).
It is particularly well-suited for binary dependent variables, such as predicting default versus no default. The logistic model generates probability scores between 0 and 1, directly representing the likelihood of default, making the results intuitive and straightforward to interpret. The interpretability of the logistic regression model is a key advantage. Additionally, the coefficients in a logistic regression model offer clear insights into the influence of each predictor on the probability of default, further enhancing the model’s interpretability. Extensive research supports the use of logistic regression, highlighting its effectiveness in credit-scoring applications (Rudd & Priestley, 2017). By leveraging these advantages, logistic regression provides a robust and comprehensible approach to assessing credit risk.
However, the model does have notable limitations. It assumes a linear relationship between the log odds of the dependent variable and the independent variables, which may restrict its ability to capture complex or nonlinear relationships. Additionally, logistic regression does not offer a non-parametric approach, potentially limiting its effectiveness in modelling intricate patterns (Laborda & Ryoo, 2021). Despite these drawbacks, logistic regression remains popular due to its interpretability and proven track record in credit scoring.
Data set and variables
To construct the proposed credit scoring model, we need to compile data on variables deemed significant and available by each organisation, along with customer characteristics associated with default risk. This data can be sourced from financial institutions such as banks and credit unions, which maintain historical records of loans and credit applications.
Common discriminants in constructing credit scoring models include demographic factors such as age, marital status, gender, and profession and financial indicators like income, number of dependents, and credit-specific variables. These credit-specific factors encompass loan type, loan maturity, guarantees and collateral value, historical payment performance, and the length of the credit history. These variables collectively assess an individual’s likelihood and capacity to repay their debts (Vidal & Barbon, 2019; World Bank, 2019; Abdou, 2009).
It is crucial to address outliers in the dataset, which are data points that fall more than 1.5 times the interquartile range (IQR) beyond the lower or upper quartiles. Outliers can be managed by either removing them from the dataset or replacing them with a more typical value, such as the mean, or by capping them at a specified value. Additionally, unusual data points should be examined to understand their impact on the distribution and overall insights of the dataset. Proper handling of these outliers ensures the integrity and accuracy of the credit scoring model.
Methodology
The process of using a logistic regression model to produce credit scores involves several key steps.
First of all, select relevant variables and address any outliers, and use the forward-looking default within the next 12 months as the dependent variable.
To deal with potential multicollinearity among predictor variables, the Variance Inflation Factor (VIF) method eliminates highly correlated variables (choose a threshold cut-off value). The VIF method can be used before or after calculating the Weight of Evidence (WOE). This might be relevant if the WOE transformation significantly changes the relationship between variables and thus alters the multicollinearity structure.
Then, categorise variables into appropriate discrete Weight of Evidence (WOE) bins. The simplest method to achieve this is using the `woebin` function in R. Variables often come in various formats, including numerical and categorical. Binning these variables makes the data more accessible and understandable, facilitating better model performance and interpretation (Rachmanto, 2023).
Generally, the WOE method has lots of advantages, such as the capability to handle missing values and the variable’s non-linearity, as well as to maintain the interpretability of the model after the transformation (Wang et al., 2022). Whereas, Persson (2021) reports that, on highly unbalanced datasets, the performance of existing WOE estimation algorithms could be better. These algorithms can cause substantial fluctuations in a customer’s credit score when their financial ratios shift between bins. Persson’s findings indicate that, compared to models that do not use WOE-transformed variables, the introduction of WOE transformation generally diminishes the model’s discriminatory power across most evaluation metrics. In contrast, empirical research by Yang et al. (2015) demonstrates that logistic regression models incorporating WOE can perform well. Additionally, other studies, such as Seitshiro and Govender (2024), support the efficacy of logistic regression with WOE for credit scoring, suggesting that, despite some challenges, WOE can still be a valuable tool in certain contexts.
The new WOE explanatory variables can be formulated by:
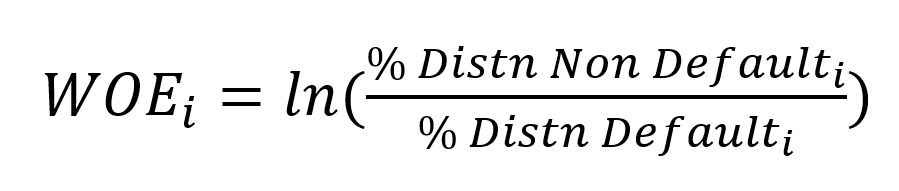
Once we have got the WOE values, we then apply stepwise logistic regression. Stepwise logistic regression is an automatic variable selection technique that aims to find the optimal subset of predictors for a logistic regression model (“Stepwise Logistic Regression in R: A Complete Guide,” 2023).
The formula used to perform multiple logit regression using stepwise selection on the WOE variables is the following:
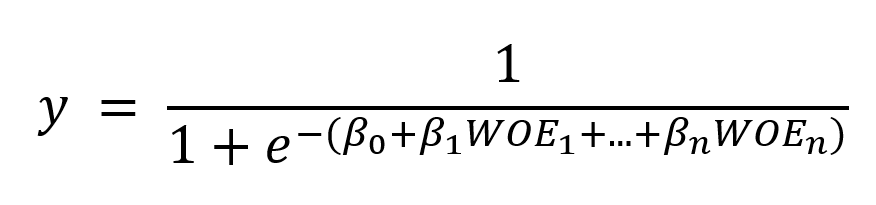
Similarly, information value (IV) can also help with variable selection. IV is a statistical measure used to evaluate the predictive power of a variable in distinguishing between binary classes. It quantifies how well a variable can separate different outcomes by assessing the strength of its relationship with the target variable. As can be seen in table 1, a higher IV indicates a stronger predictive ability, making it a valuable tool for variable selection. By comparing IV values across different variables, one can identify which features are most effective in predicting the target outcome, thereby improving model performance and interpretability (Saputra et al., 2023).
IV can be calculated by:
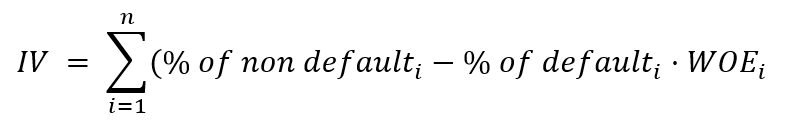
| Information Value (IV) | Predictive Power of the Variable |
| < 0.02 | Useless for prediction |
| 0.02 to 0.10 | Weak predictor |
| 0.10 to 0.30 | Medium predictor |
| 0.30 to 0.50 | Strong predictor |
| > 0.5 | Suspicious behaviour |
Source: K2 Analytics
Lastly, to transform the probability of default into a credit score, re-express the multiple logit regression formula in terms of log odds:
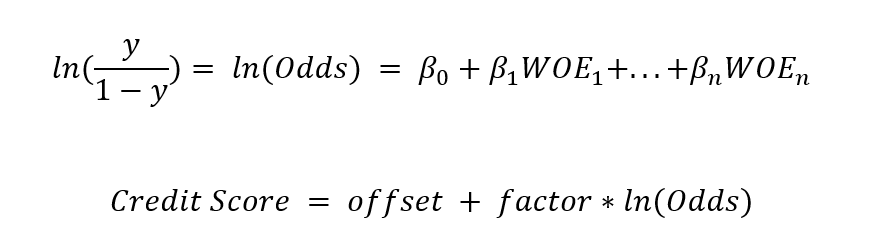
Thus, by combining the equations, we get:
Credit Score = Base Score + Contributions by WOE transformed Predictors
Where
Applying the model to Thai SMEs
Based on research conducted by Tangsawasdirat et al. (2021), the credit scoring model applied to Thai SMEs is developed using the intersection of the Loan Arrangement (LAR) database, SMEs Data (SMD) database, and the Corporate Profile and Financial Statement (CPFS) database as the dataset used for analysis.
The explanatory variables are based on default-related financial and non-financial SME data.
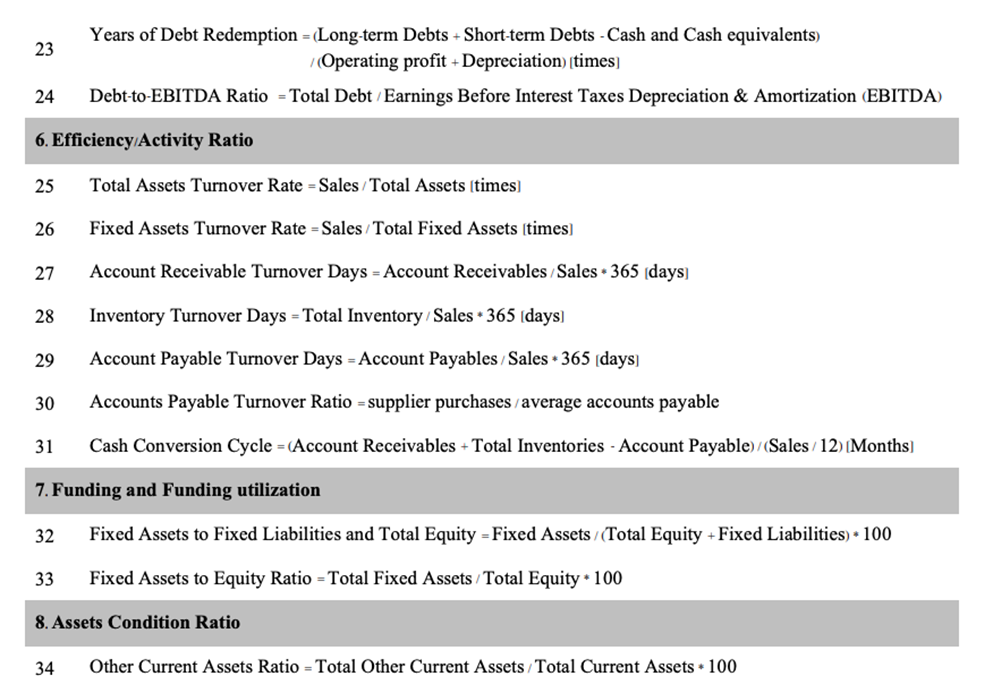
We can compute 34 financial ratios (Appendix A) that will be used as the explanatory variables by creating accounting variables from the dataset and combining nine non-financial indicators: firm age, authorised shareholding capital, loan size, ISIC, SME size, Registration Type, Years of financial statements, Province and Region. This example utilised financial and non-financial information gathered by the Department of Business Development (DBD) and the Ministry of Commerce, along with loan data from financial institutions regulated by the Bank of Thailand.
To develop a credit scoring model, follow the previously outlined steps. Begin by examining the data distribution, identifying any outliers, and using the VIF method to eliminate any variables with multicollinearity (added in just now). Next, the Weight of Evidence (WOE) transformation is applied to the variables to convert them into a format suitable for modelling. Then, perform multiple logit regression using stepwise selection and calculate the credit scores based on the transformed data. Tangsawasdirat et al. (2021) evaluated the model’s performance by comparing the credit scores generated for the test data with those from the training data. Their analysis revealed that the test data’s credit score distributions for both default and non-default groups closely mirrored those in the training data. This consistency indicates that the model generalises well and fits the data effectively.
Alternative data
When there is a lack of information to assess an individual’s creditworthiness, alternative data can enhance the evaluation process. Literature supports several such variables:
According to the World Bank (2019) and also supported by Blazquez & Domenech (2018), analysing the quantity and regularity of social media posts can provide valuable insights into a consumer’s lifestyle, spending habits, and willingness to repay debt. This information can help fill gaps in traditional credit assessments.
Another helpful source is the analysis of utility bill payment history. This approach is based on the premise that past payment behaviour reflects an individual’s ability to manage and repay debt. Consistent and timely payments on utility bills can indicate a reliable repayment pattern (World Bank, 2019).
Educational attainment is also a significant predictor of creditworthiness. Research by Lusardi and Mitchell (2011) on financial literacy and retirement found a strong correlation between higher levels of education and improved financial decision-making. Higher educational achievement is often associated with better financial responsibility, increased career stability, and prudent financial behaviours. Including educational attainment as a variable in credit scoring models can thus provide additional insights into an individual’s financial reliability.
These alternative variables offer valuable supplements to traditional credit data, helping to create a more comprehensive assessment of creditworthiness.
Conclusion
In conclusion, this paper has outlined the process of developing a credit scoring model using logistic regression, highlighting its advantages and practical applications. By leveraging logistic regression’s ability to handle binary outcomes and provide intuitive probability scores, the model offers clear insights into the likelihood of default. The methodology involves examining data distributions, addressing outliers, and applying the Weight of Evidence (WOE) transformation to categorical variables. The analysis of Thai SMEs, as demonstrated by Tangsawasdirat et al. (2021), shows that the model effectively generalises across different datasets, with credit score distributions for default and non-default groups aligning well between training and test data. This consistency underscores the model’s robustness and suitability for real-world credit risk assessment.
Furthermore, in cases where traditional credit data is scarce, alternative variables can enhance the evaluation process. Insights from social media activity, utility bill payment history, and educational attainment provide valuable supplementary information that can improve the accuracy of credit scoring models. These alternative variables, supported by literature, offer a more comprehensive view of an individual’s financial behaviour and reliability. Incorporating such variables into credit scoring models can address data gaps and refine risk assessment, leading to more accurate and reliable credit evaluations.
Finally, we would like to express our sincere gratitude to Dr. Norabaja Assava-vallop, Dr. Kawin Iamtrakul, and the entire Macroeconomic team, for this exceptional opportunity and guidance in producing this paper.
Appendix A

References
Abdou, H.A. (2009) ‘Genetic programming for credit scoring: The case of egyptian public sector banks’, Expert Systems with Applications, 36(9), pp. 11402–11417. doi:10.1016/j.eswa.2009.01.076.
Altman, E.I. and Sabato, G. (2005) ‘Modeling credit risk for smes: Evidence from the US market’, SSRN Electronic Journal [Preprint]. doi:10.2139/ssrn.872336.
Blazquez, D., & Domenech, J. (2018). Big Data sources and methods for social and economic analyses. Technological Forecasting and Social Change, 130, 99–113. https://doi.org/10.1016/j.techfore.2017.07.027
Laborda, J. and Ryoo, S. (2021) ‘Feature selection in a credit scoring model’, Mathematics, 9(7), p. 746. doi:10.3390/math9070746.
Lusardi, A., & Mitchell, O. S. (2011). Financial Literacy and Planning: Implications for Retirement wellbeing. https://doi.org/10.3386/w17078
Mester, L.J. (1997) What is the point of credit scoring? Available at: https://www.researchgate.net/publication/5051659_What_Is_the_Point_of_Credit_Scoring (Accessed: 10 August 2024).
Persson, R. (2021) Weight of evidence transformation in credit scoring models: How does it affect the discriminatory power? Available at: http://lup.lub.lu.se/student-papers/record/9066332 (Accessed: 10 August 2024).
Rachmanto, R. (2023) Logistic regression in building credit scorecard, Medium. Available at: https://medium.com/@rachmanto.rian/logistic-regression-in-building-credit-scorecard-924bece9f953 (Accessed: 10 August 2024).
Rudd, MPH, GStat, J.M. and Priestley, J. L., “A Comparison of Decision Tree with Logistic Regression Model for Prediction of Worst Non-Financial Payment Status in Commercial Credit” (2017). Grey Literature from PhD Candidates. 5.
Saputra, M. D., Fitria, Z., Sartono, B., Ramadhani, E., & Hadi, A. F. (2023). Weight of Evidence and Information Value on Support Vector Machine Classifier. In Advances in intelligent systems research/Advances in Intelligent Systems Research (pp. 113–124). https://doi.org/10.2991/978-94-6463-174-6_11
Seitshiro, M. B., & Govender, S. (2024). Credit risk prediction with and without weights of evidence using quantitative learning models. Cogent Economics & Finance, 12(1). https://doi.org/10.1080/23322039.2024.2338971
Stepwise Logistic Regression in R: A Complete Guide. (2023, August 7). Medium. https://rstudiodatalab.medium.com/stepwise-logistic-regression-in-r-a-complete-guide-82fcd9e2d389
Tangsawasdirat, B., Tangsatchanan, B. and Tanpoonkiat, S. (2021) Credit Risk Database: Credit Scoring Models For Thai SMEs, Puey Ungphakorn Institute For Economic Research (PIER). Available at: https://www.pier.or.th/files/dp/pier_dp_168.pdf (Accessed: 10 August 2024).
Vidal, M.F. and Barbon, F. (2019) How to use advanced analytics to build credit-scoring models that increase access, CGAP. Available at: https://www.cgap.org/sites/default/files/publications/2019_07_Technical_Guide_CreditScore_0.pdf (Accessed: 10 August 2024).
World Bank (2019) CREDIT SCORING APPROACHES GUIDELINES, www.worldbank.org. Available at: https://thedocs.worldbank.org/en/doc/935891585869698451-0130022020/original/CREDITSCORINGAPPROACHESGUIDELINESFINALWEB.pdf (Accessed: 10 August 2024).
Wang, H. et al. (2022) A two-staged local regression based Binning method for …, SESUG. Available at: https://sesug.org/proceedings/sesug_2022_final_papers/Industry_Applications/SESUG2022_Paper_188_Final_PDF.pdf (Accessed: 10 August 2024).
Yang, X., Zhu, Y., Yan, L., & Wang, X. (2015). Credit Risk Model Based on Logistic Regression and Weight of Evidence. https://doi.org/10.2991/msetasse-15.2015.180



Nami Hama
ผู้เขียน

Roy Melville
ผู้เขียน