
บทความโดย
ดร.กวิน เอี่ยมตระกูล[1]
[1] ผู้เขียน ดร.กวิน เอี่ยมตระกูล เศรษฐกรชำนาญการ ขอขอบคุณ ดร.พิสิทธิ พัวพันธ์ ดร.นรพัชร์ อัศววัลลภ ดร.ยุทธภูมิ จารุเศร์นี และนางสาวอภิญญา เจนธัญญารักษ์ สำหรับคำแนะนำ ทั้งนี้ ข้อคิดเห็นที่ปรากฏในบทความนี้เป็นความเห็นของผู้เขียน ซึ่งไม่จำเป็นต้องสอดคล้องกับความเห็นของสำนักงานเศรษฐกิจการคลัง
บทคัดย่อ
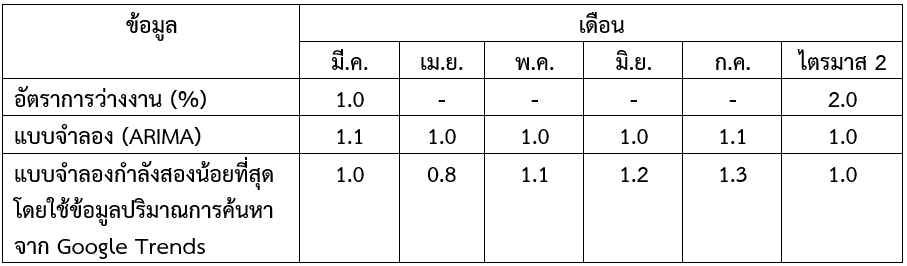
งานศึกษาฉบับนี้ ได้นำประโยชน์จากฐานข้อมูลขนาดใหญ่ (Big Data) ของ Google ในแอพพลิเคชั่น Google Trends ซึ่งมีศักยภาพเพียงพอในการเป็นเครื่องชี้วัดเศรษฐกิจโดยแสดงพฤติกรรมความสนใจของประชาชนทุกระดับและแสดงผลแบบ Real Time มาใช้ในการติดตามและประเมินผลเศรษฐกิจด้านการว่างงานของไทย โดยในงานศึกษาฉบับนี้ประมาณการอัตราการว่างงานระหว่างเดือนเมษายน – กรกฎาคม 2563 โดยเปรียบเทียบผลการทดสอบระหว่าง 1) แบบจำลอง ARIMA (Auto Regressive and Moving Average) โดยใช้ข้อมูลอัตราการว่างงานในอดีต และ 2) แบบจำลองกำลังสองน้อยที่สุดที่ใช้ข้อมูลปริมาณการค้นหาจาก Google Trends ของคำว่า “สมัครงาน” และ “หางาน” ทั้งนี้ ผลการศึกษาพบว่า แบบจำลองกำลังสองน้อยที่สุด โดยใช้ข้อมูลปริมาณการค้นหาจาก Google Trends ประมาณการอัตราการว่างงาน ในเดือนเมษายน – กรกฎาคม 2563 ในช่วงร้อยละ 0.8 ถึง 1.3 และให้ค่าเฉลี่ยความคลาดเคลื่อนกำลังสองต่ำที่สุด โดยต่ำกว่าแบบจำลอง ARIMA ที่ประมาณการอัตราการว่างงานที่ร้อยละ 1.0 ถึง 1.1 เนื่องจากคนส่วนใหญ่ให้ความสนใจในการค้นหาคำว่า “เราไม่ทิ้งกัน” มากที่สุดในช่วงเวลาดังกล่าว แต่ภายหลังที่มาตรการเยียวยาสิ้นสุดลง กอรปกับสถานการณ์ทางเศรษฐกิจที่ชะลอตัวลง ภาคธุรกิจได้รับผลกระทบมากขึ้น ประชาชนจึงให้ความสนใจในการค้นหาคำว่า “สมัครงาน” และ “หางาน” มากยิ่งขึ้น ตั้งแต่เดือนมิถุนายนเป็นต้นมา ทั้งนี้ แม้ว่าแบบจำลองกำลังสองน้อยที่สุดประมาณการอัตราการว่างงานไตรมาสที่สอง 2563 ที่ร้อยละ 1.0[2] ต่ำกว่าอัตราการว่างงานไตรมาสที่สองที่สำนักงานสถิติแห่งชาติเผยแพร่ ที่ร้อยละ 2.0 หรือมีผู้ว่างงานจำนวน 7.45 แสนคน จากจำนวนแรงงาน 38.17 ล้านคน และมีผู้มีงานทำ ซึ่งขณะนี้ไม่ได้ทำงานและไม่ได้รับเงินเดือน แต่มีงานที่จะกลับไปทำจำนวน 2.08 ล้านคน หากแต่การมีข้อมูลเบื้องต้นที่มีความถี่เป็นรายเดือน ก็มีส่วนช่วยให้ติดตามภาวะเศรษฐกิจได้อย่างทันท่วงที อย่างไรก็ดี การนำข้อมูลปริมาณการค้นหาจาก Google Trends มาใช้ จำเป็นต้องมีความระมัดระวังในการคัดเลือกคำค้นหา การเลือกคำที่แตกต่างกัน หรือคำเดียวกัน แต่คนละช่วงเวลา ผลลัพธ์ก็จะมีความแตกต่างกัน
[2] แบบจำลองกำลังสองน้อยที่สุดประมาณการอัตราการว่างงาน เดือนเมษายน 2563 ถึงเดือนมิถุนายน 2563 เท่ากับร้อยละ 0.8 1.1 และ 1.2 ตามลำดับ
1.บทนำ
ในยุคที่การติดต่อสื่อสารเป็นไปอย่างสะดวกและรวดเร็วขึ้น อินเทอร์เน็ตเริ่มเข้ามามีบทบาทในการเป็นแหล่งฐานข้อมูลขนาดใหญ่ (Big Data) ที่มีประโยชน์ในการติดตามพฤติกรรมและความสนใจของประชาชนทุกระดับ โดยข้อมูลบางส่วนที่ได้เผยแพร่สู่สาธารณะ มีส่วนช่วยให้ผู้ใช้บริการทั้งภาครัฐและภาคเอกชนนำความนิยมของคำค้นหาที่หลากหลายจากฐานข้อมูลขนาดใหญ่นี้ มาใช้ในการวิเคราะห์ความต้องการของกลุ่มเป้าหมายได้อย่างตรงจุดและทั่วถึง เช่น คำค้นหา “โทรทัศน์ดิจิตอล” เป็นคำที่ได้รับความนิยมในระยะหลังมานี้ แทนที่คำว่า “โทรทัศน์” ซึ่งการเปลี่ยนแปลงคำค้นหาดังกล่าว สะท้อนความต้องการสินค้าคงทนของผู้บริโภคที่เปลี่ยนไปตามเวลา
ปัจจุบันเว็ปไซต์ Google ถือเป็นแหล่งฐานข้อมูลขนาดใหญ่ (Big Data) เนื่องจากรวบรวมข้อมูลการค้นหาของประชาชนในทุกระดับทั่วโลก และ Google ได้พัฒนาแอปพลิเคชันที่มีชื่อว่า Google Trends ซึ่งแสดงปริมาณการค้นหาแบบ Real Time ที่สะท้อนพฤติกรรมความสนใจของผู้ใช้งานที่เกิดขึ้นเป็นประจำทุกวัน โดยข้อมูลปริมาณการค้นหาจาก Google Trends สามารถ Export ให้อยู่ในรูปข้อมูลอนุกรมเวลาได้เป็นรายชั่วโมง รายสัปดาห์ รายเดือนและรายปี โดยมีข้อมูลย้อนหลังถึงปี 2547 และสามารถแยกประเภทการค้นหาได้เป็นรายจังหวัดที่แสดงผลในรูปแผนที่ รวมถึงแสดงหัวข้ออื่นที่เป็นคำนิยมในการค้นหาเช่นกัน ทั้งนี้ ความนิยมในปริมาณการค้นหาถูกปรับให้อยู่ในรูปดัชนี (Index) ซึ่งคำนวณจากสัดส่วนระหว่างจำนวนคำที่ใช้ในการค้นหาและจำนวนการค้นหาทั้งหมดระหว่างสัปดาห์ อีกทั้งยังได้ขจัดผลทางฤดูกาล (Seasonal Factors) ออกไปแล้ว โดยดัชนีมีค่าเป็นตัวเลข ระหว่าง 0-100 โดยค่า 100 หมายถึง คำที่มีความนิยมสูงสุดและมีปริมาณการค้นหามากที่สุด ส่วนค่า 0 หมายถึง ข้อมูลไม่เพียงพอในการประมวลผล อย่างไรก็ดี การนำข้อมูล Google Trends มาใช้ยังมีข้อจำกัด คือ การค้นหาคำประเภทเดียวกัน แต่คนละวัน ผลลัพธ์จะแตกต่างกัน ดังนั้น การนำเข้ามูลจาก Google Trends มาใช้ ควรเป็นข้อมูลเฉลี่ยรายเดือน เนื่องจาก มีเสถียรภาพมากกว่าข้อมูลรายวันที่มีการเปลี่ยนแปลงรายวัน
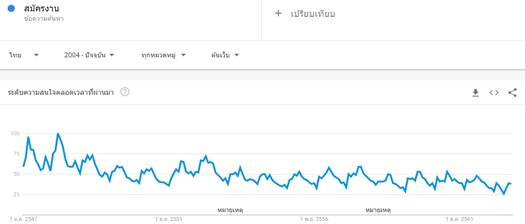
ที่มา : Google Trends ข้อมูล ณ วันที่ 3 สิงหาคม 2563

ที่มา : Google Trends ข้อมูล ณ วันที่ 3 สิงหาคม 2563
ภาพที่ 1 และ 2 แสดงตัวอย่างการค้นหาคำว่า “สมัครงาน” พบว่า ผลลัพธ์มีแนวโน้มลดลงอย่างต่อเนื่องตั้งแต่ปี 2554 เป็นต้นมา ซึ่งสะท้อนว่าคนส่วนใหญ่อาจมีงานที่ตนพึงพอใจทำอยู่แล้ว จึงไม่มีความจำเป็นที่จะต้องหางานใหม่ อย่างไรก็ดี ในช่วงที่เศรษฐกิจไทยได้รับผลกระทบจากการแพร่ระบาดของโรคติดเชื้อไวรัสโคโรนา 2019 ตั้งแต่เดือนเมษายน 2563 ถึงปัจจุบัน ประชาชนก็เริ่มมีการค้นหาคำดังกล่าวมากขึ้น แสดงถึงความต้องการหางานเพิ่มมากขึ้นจากการที่ธุรกิจต่าง ๆ ได้รับผลกระทบและไม่สามารถดำเนินการได้ในช่วงที่รัฐบาลออกมาตรการควบคุมการแพร่ระบาด เป็นเหตุทำให้แรงงานบางส่วนถูกเลิกจ้างหรือพักงาน โดยปริมาณความถี่ในการค้นหาคำดังกล่าวมีค่าเท่ากับ 38 ณ สิ้นเดือนกรกฎาคม 2563 ในขณะที่ช่วงราว 15 ปีที่ผ่านมาเคยอยู่ที่ระดับ 100 โดยกลุ่มตัวอย่างที่สนใจค้นหาเป็นอันดับแรกอาศัยอยู่ในจังหวัดนนทบุรี รองลงมากลุ่มตัวอย่างที่อาศัยอยู่ที่จังหวัดกรุงเทพฯ และปริมณฑล
อัตราการว่างงานถือเป็นเครื่องชี้สำหรับติดตามภาวะเศรษฐกิจที่สำคัญ ในช่วงเศรษฐกิจตกต่ำ อัตราการว่างงานค่อนข้างสูง ในช่วงภาวะเศรษฐกิจขยายตัว อัตราการว่างงานจะลดลง ดังนั้น อัตราการว่างงานจึงสามารถใช้เป็นข้อมูลพื้นฐานในการวางแผนนโยบายและการจัดสรรงบประมาณของหน่วยงานที่เกี่ยวข้องได้เป็นอย่างดี นอกจากนี้ McLaren and Rachana (2011) ได้ใช้ประโยชน์จาก Google Trends ในการติดตามภาวะเศรษฐกิจด้านตลาดแรงงาน (Labor Market) เนื่องจากคนที่กำลังหางานหรือมีความกังกลว่าจะตกงานอาจจะค้นหาข้อมูลทางอินเทอร์เน็ตเกี่ยวข้องกับการประกันสังคมหรือการหางานใหม่ และได้คัดเลือกคำ “JSA” (Jobseeker’s Allowance)”[3] เนื่องจากข้อมูลมีทิศทางไปในทางเดียวกับการว่างงาน และคำนี้สะท้อนพฤติกรรมของลูกจ้างและพนักงานที่มีแนวโน้มที่จะตกงาน ในการค้นหาข้อมูลผลประโยชน์จากการว่างงาน (Unemployment Benefits) โดยผลการประมาณสมการถดถอย (Forecasting) ของข้อมูลเดือนกรกฎาคม 2551 พบว่า ค่าเฉลี่ยของความคลาดเคลื่อน (RMSE) ของ คำค้นหา “JSA” มีค่าเท่ากับร้อยละ 35.3 ต่ำกว่าตัวเลขการว่างงานจริงที่มีค่าร้อยละ 40.4
[3] คำที่ใช้ในการค้นหาเกี่ยวกับตลาดแรงงานทั้งหมด ได้แก่ Jobs, Jobseeker’s, Allowance, Jobseeker’s Allowance (JSA), Unemployment Benefit, Unemployed และ Unemployment
อย่างไรก็ตาม สถานการณ์เศรษฐกิจในปัจจุบันได้เปลี่ยนแปลงอย่างรวดเร็ว ในขณะที่ข้อมูลอัตราการว่างงานของสำนักงานสถิติแห่งชาติที่เผยแพร่เป็นรายไตรมาสนั้น ข้อมูลล่าสุด ณ เดือนสิงหาคม 2563 อัตราการว่างงานไตรมาสที่สองอยู่ที่ร้อยละ 2.0 ซึ่งอาจไม่เพียงพอในการนำมาติดตามภาวะเศรษฐกิจไทยได้อย่างทันท่วงที ดังนั้น งานศึกษาฉบับนี้จึงใช้ประโยชน์การปริมาณการค้นหาจาก Google Trends มาใช้ในการประมาณการอัตราการว่างงานรายเดือน ตั้งแต่เดือนเมษายนถึงเดือนกรกฎาคม 2563
ทั้งนี้ ปริมาณการค้นหาจาก Google Trends ยังมีข้อจำกัด คือ ไม่สามารถบ่งบอกปริมาณหรือขนาดของธุรกรรมในแต่ละประเภทได้ ดังนั้น การนำข้อมูลจาก Google Trends มาใช้จำเป็นต้องพึงระวังการคัดกรองคำ ซึ่งจำเป็นต้องสะท้อนและมีนัยสำคัญทางเศรษฐกิจที่แท้จริง ทั้งนี้ งานศึกษาฉบับนี้ได้ใช้เกณฑ์ในการคัดกรองคำจากงานศึกษาของ ปภัสสร (2018) ซึ่งมี จำนวน 4 เกณฑ์ ดังนี้
1. เกณฑ์คัดกรองคำที่ 1: คำในการค้นหาต้องไม่ใช่คำเฉพาะเจาะจง เช่น ชื่อยี่ห้อ ชื่อสถานที่ ชื่อรุ่นสินค้า
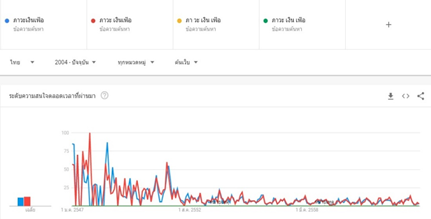
2. เกณฑ์คัดกรองคำที่ 2: คำในการค้นหาต้องได้รับความนิยมเพียงพอ ไม่ใช่คำที่ได้รับความนิยมในระยะหลัง หากเป็นเช่นนั้นความถี่ในการค้นหาในช่วงก่อนหน้าจะมีค่าผลลัพธ์เท่ากับ 0 ซึ่งจะไม่สะท้อนพฤติกรรมของผู้บริโภคที่เกี่ยวข้องกับวัฏจักรเศรษฐกิจ เช่น บัตรสวัสดิการแห่งรัฐ ชิมช้อบใช้ เราไม่ทิ้งกัน เราเที่ยวด้วยกัน เป็นต้น รายละเอียดตามภาพที่ 3

ที่มา : Google Trends ข้อมูล ณ วันที่ 3 สิงหาคม 2563
3. เกณฑ์คัดกรองคำที่ 3: คำค้นหาที่มีลักษณะเดียวกัน แต่มีลักษณะการเว้นวรรคที่แตกต่างกันต้องไม่มีความแตกต่างอย่างมีนัยสำคัญ เช่น “ภาวะเงินเฟ้อ” “ภาวะ เงินเฟ้อ” “ภา วะ เงิน เฟ้อ” “ภาวะ เงิน เฟ้อ ” รายละเอียดตามภาพที่ 4
ที่มา : Google Trends ข้อมูล ณ วันที่ 3 สิงหาคม 2563
4. เกณฑ์คัดกรองคำที่ 4[4]: คำในการค้นหาต้องมีความหมายและมีนัยทางเศรษฐกิจ
[4] งานศึกษาของ ปภัสสร (2018) จะมีเกณฑ์ในการคัดกรองคำจำนวน 5 เกณฑ์ อย่างไรก็ตาม งานศึกษาฉบับนี้ได้ตัดเกณฑ์คัดกรองเรื่องค่าสหสัมพันธ์ (Correlation) กับตัวแปรที่เกี่ยวข้องที่สูงกว่า 0.5 ออกไป เนื่องจาก ค่าสหสัมพันธ์มักมีค่าแตกต่างกันไปขึ้นอยู่กับระยะเวลาที่นำมาใช้คำนวณ
3.วิธีการศึกษา
3.1 การทดสอบความนิ่งของข้อมูล (Stationary)
ข้อมูลอนุกรมเวลา (Time Series Data) คือ ชุดข้อมูลที่มีการเก็บรวบรวมและเรียงลำดับของเวลาอย่างต่อเนื่อง โดยการจัดเรียงข้อมูลอาจมีลักษณะเป็นรายปี (Yearly) รายไตรมาส (Quarterly) รายเดือน (Monthly) รายสัปดาห์์ (Weekly) รายวัน (Daily) หรือรายชั่วโมง (Hourly) เป็นต้น ตัวอย่างเช่น ข้อมูลอัตราแลกเปลี่ยนไทยบาทต่อดอลลาร์สหรัฐอเมริการายวัน ตั้งแต่วันที่ 1 มกราคม ถึงวันที่ 30 กรกฎาคม 2563
ทั้งนี้ ก่อนนำข้อมูลอนุกรมเวลามาใช้วิเคราะห์ในทางเศรษฐมิติจะต้องทำการทดสอบว่าข้อมูลมีความสัมพันธ์ร่วมกับเวลาหรือไม่ โดยปกติข้อมูลอนุกรมเวลาของเครื่องชี้เศรษฐกิจมหภาคจะผันแปรไปตามเวลา นั้นคือ เครื่องชี้มีการเคลื่อนไหวไปตามแนวโน้มที่เพิ่มขึ้นตามกาลเวลา หรือเครื่องชี้มีลักษณะไม่นิ่ง (Non-stationary) หากนำข้อมูลลักษณะนี้มาใช้วิเคราะห์จะไม่สามารถอธิบายลักษณะความสัมพันธ์ระหว่างตัวแปรได้อย่างแท้จริง หรือเกิดปัญหาความสัมพันธ์ปลอม (Spurious Regression) ซึ่งวิธีการทดสอบมี 3 วิธี ได้แก่
1) การสร้างกราฟ[5] 2) แผนภาพสหสัมพันธ์ (Correlogram)[6] และ 3) การทดสอบทางเศรษฐมิติด้วยวิธี Augmented Dickey-Fuller Test Statistic และงานศึกษาในครั้งนี้ผู้เขียนจะทำการทดสอบความนิ่งด้วย 1) วิธีการสร้างกราฟและ 2) วิธี Augmented Dickey-Fuller Test Statistic ตามแนวคิดของ Dickey and Fuller (1979,1981)
[5] การสร้างกราฟเพื่อดูความสัมพันธ์ระหว่างเครื่องชี้กับเวลา หากมูลค่าของเครื่องชี้เพิ่มขึ้นเมื่อเวลาเปลี่ยนแปลงไป แสดงว่าข้อมูลมีลักษณะไม่นิ่ง (Non- stationary)
[6] การสร้างแผนภาพสหสัมพันธ์ (Correlogram) เพื่อดูความสัมพันธ์ระหว่างเครื่องชี้ในปัจจุบันกับตัวของมันเองในอดีต หากข้อมูลมีลักษณะนิ่ง (Stationary) รูปที่แสดงต้องไม่มีลักษณะลดลงแบบ Exponential
ในงานศึกษาเบื้องต้นจะทดสอบความนิ่ง (Stationary) ของข้อมูลอัตราการว่างงาน และคำค้นหาจาก Google Trends ได้แก่ “สมัครงาน” และ “หางาน” ซึ่งเมื่อใช้วิธีการสร้างกราฟ ภาพที่ 5 จะพบว่าข้อมูลเครื่องชี้ทั้ง 3 ประเภทไม่มีการเคลื่อนไหวไปตามแนวโน้มที่เพิ่มขึ้นตามกาลเวลา และเมื่อทดสอบด้วย Dickey-Fuller Test Statistic พบว่า ค่า Dickey-Fuller Test Statistic ของเครื่องชี้ทุกตัวมีนัยสำคัญทางสถิติ ณ ระดับความเชื่อมั่นร้อยละ 1 แสดงว่า มีการปฏิเสธสมมติฐานหลัก (H0) ที่ทดสอบว่าข้อมูลนิ่งหรือไม่ และยอมรับสมมติฐานรอง (H1) นั้นคือ ข้อมูลมีลักษณะนิ่ง (Stationary) ดังนี้ งานวิจัยฉบับนี้จึงไม่มีความจำเป็นที่จะต้องอัตราการเปลี่ยนแปลงรายปี (y-o-y) หรือแยกองค์ประกอบปัจจัยแนวโน้ม (Trends) ออกจากปัจจัยวัฏจักรเศรษฐกิจ (Cycle)
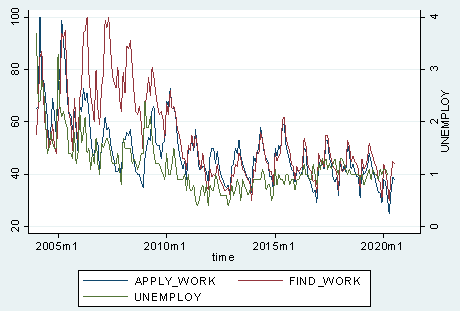
ที่มา: คำนวณโดยผู้เขียน
อย่างไรก็ดี ข้อสังเกตที่เด่นชัดของ ภาพที่ 5 คือ ข้อมูลปริมาณการค้นหาจาก Google Trends คำว่า “สมัครงาน” และ “หางาน” มีลักษณะค่อนข้างไปในทิศทางเดียวกันกับข้อมูลอัตราการว่างงาน ดังนั้น ข้อมูลดังกล่าวจึงมีศักยภาพเพียงพอที่จะนำมาใช้เบื้องต้นในการประมาณอัตราการว่างงานในอนาคต
3.2 การคัดเลือกแบบจำลอง
ภายหลังจากที่ได้ข้อมูลเครื่องชี้ที่มีลักษณะนิ่งแล้ว ลำดับถัดไปคือ การสร้างแบบจำลองในการประมาณการอัตราการว่างงานเดือนเมษายน – เดือนกรกฎาคม 2563 โดยงานศึกษาฉบับนี้จะใช้สร้างแบบจำลองทาง เศรษฐมิติจำนวน 2 แบบจำลอง ได้แก่ 1) แบบจำลอง Autoregressive Integrated Moving Average Model (ARIMA) เนื่องจากเป็นวิธีที่มีขั้นตอนไม่ยุ่งยากและซับซ้อน โดยใช้เพียงข้อมูลที่เราสนใจจะทดสอบเพียงตัวเดียว และมีค่าเฉลี่ยของความคลาดเคลื่อนกำลังสอง (Root Mean Square Error: RMSE) ของการพยากรณ์ที่ต่ำกว่า วิธีอื่น และ 2) แบบจำลองกำลังสองน้อยที่สุด (Least Squares) ซึ่งศึกษาความสัมพันธ์ที่ตัวแปรหนึ่งที่ส่งผลต่อ อีกค่าของตัวแปรหนึ่ง โดยในที่นี้ ผู้เขียนจะศึกษาความสัมพันธ์ระหว่างอัตราการว่างงานและปริมาณการค้นหาจาก Google Trends ได้แก่ “สมัครงาน” และ “หางาน”
4.ผลการศึกษา
สำหรับวิธีการที่ใช้คัดเลือกแบบจำลองที่ดีที่สุดนั้น โดยทั่วไปจะใช้ความเห็นของผู้จัดทำค่อนข้างสูง (Judgement) อย่างไรก็ดี งานศึกษาฉบับนี้ได้กำหนดเกณฑ์การคัดกรองแบบจำลอง จำนวน 3 เกณฑ์ ดังนี้
1. การตรวจสอบค่านัยสำคัญทางสถิติของแต่ละเครื่องชี้ หากเครื่องชี้ใดไม่มีนัยสำคัญทางสถิติก็ต้องคัดออกจนกระทั่งได้แบบจำลองที่ทุกเครื่องชี้มีนัยสำคัญทางสถิติทั้งหมด
2. การคัดเลือกแบบจำลองที่ค่า R-squared สูงที่สุด ทั้งนี้ R-squared คือ ค่าที่บ่งชี้ว่าตัวแปรอิสระทั้งหมดสามารถอธิบายความผันแปรของตัวแปรตามที่อยู่ในแบบจำลองได้ร้อยละเท่าไร โดยปกติจะมีค่าอยู่ระหว่างร้อยละ 0 -100 กล่าวคือ ยิ่งค่าสูงมากเท่าใด (ค่าใกล้ ร้อยละ 100) ย่อมแสดงให้เห็นว่าแบบจำลองที่ได้นำมาทดสอบนั้นสามารถอธิบายความผันแปรของค่าตัวแปรตามได้เป็นอย่างดี
3. การคัดเลือกแบบจำลองที่ค่าเฉลี่ยของความคลาดเคลื่อนกำลังสอง (RMSE) มีค่าต่ำที่สุด โดยทั่วไปค่า RMSE ที่ต่ำ แสดงว่า ค่าจริงของเครื่องชี้ (Actual Value) และค่าประมาณ (Fitted Value) มีความใกล้เคียงกันนั้น คือ ตัวแปรอิสระทั้งหมดที่นำมาทดสอบสามารถพยากรณ์ตัวแปรตามที่เราสนใจได้แม่นยำ
4.1 ผลการประมาณการความสัมพันธ์ของตัวแปร
เมื่อพิจารณาผลการศึกษาในตารางที่ 1 พบว่า ทุกเครื่องชี้มีนัยสำคัญทางสถิติกับอัตราการว่างงานทั้งหมด หากใช้เกณฑ์ R-squared สูงที่สุด จะพบว่าแบบจำลอง ARIMA แสดงค่า R-squared เท่ากับร้อยละ 64.78 แต่หากใช้เกณฑ์ค่าเฉลี่ยของความคลาดเคลื่อน (RMSE) กำลังสองต่ำที่สุด จะพบว่า แบบจำลองกำลังสองน้อยแสดงค่า RMSE ต่ำกว่าแบบจำลอง ARIMA ในทุกกรณี โดยใน 3 แบบจำลองนี้การใช้ตัวแปรปริมาณการค้นหา “สมัครงาน” และ “หางาน” ควบคู่กันไปจะให้ค่า R-squared สูงสุดเท่ากับร้อยละ 52.46 และค่า RMSE ต่ำสุดเท่ากับร้อยละ 34.82 ดังนั้น ลำดับถัดไปผู้เขียนจะใช้ 1) แบบจำลอง ARIMA (1,0,2)[7] และ 2) แบบจำลองกำลังสองน้อยที่สุดที่ใช้ตัวแปรอิสระ คือ ปริมาณการค้นหาจาก Google Trends คำว่า “สมัครงาน” และ “หางาน” ในการประมาณการอัตราการว่างงานเดือนเมษายนถึงเดือนกรกฎาคม 2563
[7] งานศึกษาฉบับนี้ได้ให้โปรแกรม PYTHON และ STATA เลือกจำนวนค่าสังเกตที่เกิดขึ้นก่อนหน้า p หรือ AR(p) และหรือค่าความคลาดเคลื่อนที่อยู่ ก่อนหน้า q หรือ MA(q) ที่ให้ค่าประมาการของแบบจำลอง ARIMA ต่ำที่สุด ซึ่งมีแบบจำลองที่ใช้ในการคัดเลือกจำนวน 12 แบบจำลอง อย่างไรก็ดี เนื่องจากข้อมูลเครื่องชี้ทั้ง 3 ประเภทมีลักษณะนิ่ง (Stationary) จากที่ทดสอบไปก่อนหน้านี้ ดังนั้น จึงไม่มีความจำเป็นที่ต้องทำกระบวนการ Integrated (I(d)) และอาจกล่าวได้ว่าแบบจำลองที่ใช้ศึกษานี้เป็นแบบจำลอง Auto Regressive Moving Average หรือ ARMA ได้เช่นกัน
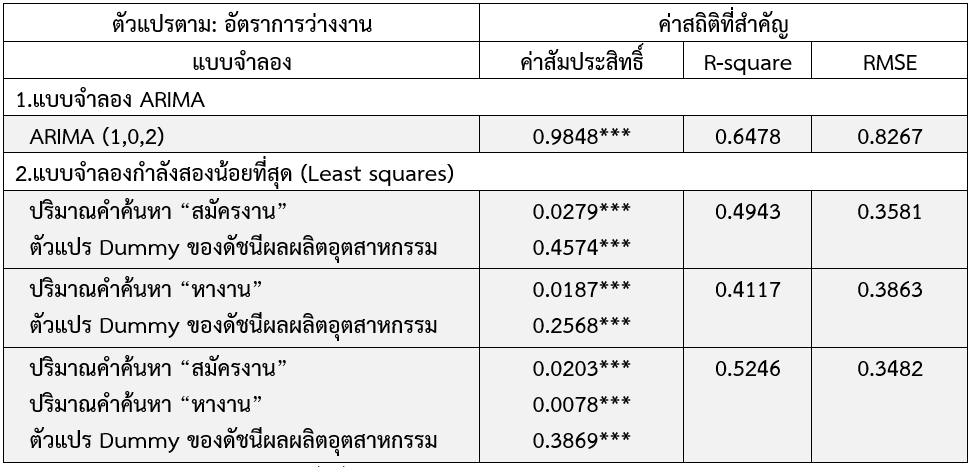
หมายเหตุ: *,**,*** ณ ระดับความเชื่อมั่นร้อยละ 1 5 และ 10 ตามลำดับ
4.2 ผลการประมาณการอัตราการว่างงาน
ภาพที่ 6 แสดงให้เห็นว่า ผลการประมาณการอัตราการว่างงานจากแบบจำลอง ARIMA และแบบจำลองกำลังสองน้อยที่สุด มีแนวโน้มไปในทิศทางเดียวกันอัตราการว่างงาน ถึงแม้ว่าขนาดของตัวเลขจะไม่เท่ากัน ทั้งนี้ ตารางที่ 2 แสดงค่าข้อมูลอัตราการว่างงานที่ประมาณการขึ้นมาจากแบบจำลอง พบว่า ตั้งแต่เดือนเมษายน เป็นต้นมา แบบจำลอง ARIMA พยากรณ์อัตราการว่างงานค่อนข้างคงที่ที่ร้อยละ 1.0 ในขณะที่แบบจำลองกำลังสองน้อยที่สุด จากปริมาณคำค้นหา Google Trends มีค่าลดลงในเดือนเมษายน และเริ่มเพิ่มขึ้นเรื่อย ๆ ในเดือนถัดไป โดย ณ เดือนกรกฎาคม อยู่ที่ร้อยละ 1.3 สอดคล้องกับปริมาณการค้นหาที่เกี่ยวข้องกับการว่างงาน เช่น “สมัครงาน”และ “หางาน” ที่ลดลงในช่วงเดือนเมษายนถึงเดือนพฤษภาคม 2563 เนื่องจากประชาชนส่วนใหญ่ให้ความสนใจในการค้นหาคำว่า “เราไม่ทิ้งกัน” มากที่สุดในช่วงเวลาดังกล่าว แต่ภายหลังที่มาตรการเยียวยาสิ้นสุดลง กอรปกับสถานการณ์ทางเศรษฐกิจที่ชะลอตัวลง ภาคธุรกิจได้รับผลกระทบมากขึ้น ประชาชนจึงให้ความสนใจในการค้นหาคำว่า “สมัครงาน”และ “หางาน” มากยิ่งขึ้น ตั้งแต่เดือนมิถุนายนเป็นต้นมา อย่างไรก็ดี แม้ว่าแบบจำลองกำลังสองน้อยที่สุดประมาณการอัตราการว่างงานไตรมาสที่สอง 2563 ที่ร้อยละ 1.0 ต่ำกว่าอัตราการว่างงานไตรมาสที่สองที่สำนักงานสถิติแห่งชาติเผยแพร่ที่ร้อยละ 2.0 หรือมีผู้ว่างงานจำนวน 7.45 แสนคน จากจำนวนแรงงาน 38.17 ล้านคน และมีผู้มีงานทำซึ่งขณะนี้ไม่ได้ทำงานและไม่ได้รับเงินเดือน แต่มีงาน ที่จะกลับไปทำจำนวน 2.08 ล้านคนหากแต่มีข้อมูลเบื้องต้นที่มีความถี่เป็นรายเดือน ก็มีส่วนช่วยให้ติดตามภาวะเศรษฐกิจได้อย่างทันท่วงที
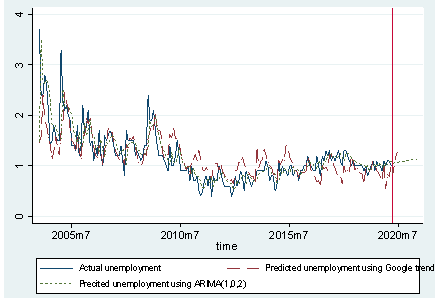
ที่มา: คำนวณโดยผู้เขียน
ที่มา: คำนวณโดยผู้เขียน
หมายเหตุ: ข้อมูลไตรมาสที่ 2 คือ ข้อมูลเฉลี่ยอัตราการว่างงานเดือนเมษายนถึงเดือนมิถุนายน 2563
5.บทสรุปและข้อเสนอแนะ
อัตราการว่างงานถือเป็นเครื่องชี้ที่สำคัญที่มีความสัมพันธ์กับอัตราการขยายตัวทางเศรษฐกิจของประเทศ โดยในช่วงที่เศรษฐกิจชะลอตัวลง อัตราการว่างงานมีแนวโน้มที่จะสูง ในทางตรงกันข้าม ช่วงที่เศรษฐกิจขยายตัว อัตราการว่างงานจะต่ำ อย่างไรก็ดี ข้อมูลอัตราการว่างงานที่จัดทำและเผยแพร่โดยสำนักงานสถิติแห่งชาติในปัจจุบันมีความล่าช้า (ข้อมูลที่นำมาใช้ ณ เดือนมีนาคม 2563) ทำให้หน่วยงานต่าง ๆ ไม่สามารถนำข้อมูลอัตราการว่างงานมาติดตามภาวะเศรษฐกิจได้ทันท่วงที จากเหตุผลดังกล่าว ผู้เขียนจึงได้นำฐานข้อมูลขนาดใหญ่ (Big Data) ของ Google ในแอพพลิเคชั่น Google Trends ซึ่งมีศักยภาพเพียงพอในการเป็นเครื่องชี้เศรษฐกิจ โดยแสดงพฤติกรรมความสนใจของประชาชนทุกระดับและแสดงผลแบบ Real Time มาใช้ในการติดตามและประเมินผลเศรษฐกิจด้านการว่างงานของไทย โดยในงานศึกษาฉบับนี้ประมาณการอัตราการว่างงานระหว่างเดือนเมษายนถึงเดือนกรกฎาคม 2563 เปรียบเทียบผลการทดสอบระหว่าง 1) แบบจำลอง ARIMA โดยใช้ข้อมูลอัตราการว่างงานในอดีต และ 2) แบบจำลองกำลังสองน้อยที่สุดที่ใช้ข้อมูลปริมาณการค้นหาจาก Google Trends ของคำว่า “สมัครงาน” และ “หางาน”
ผลการศึกษาแบบจำลองกำลังสองน้อยที่สุด โดยใช้ข้อมูลปริมาณการค้นหาจาก Google Trends ประมาณการอัตราการว่างงานในเดือนเมษายนถึงเดือนกรกฎาคม 2563 ในช่วงร้อยละ 0.8 ถึง 1.3 และให้ค่าเฉลี่ยความคลาดเคลื่อนกำลังสองต่ำที่สุด โดยต่ำกว่าแบบจำลอง ARIMA ที่ประมาณการอัตราการว่างงานที่ร้อยละ 1.0 ถึงร้อยละ 1.1 เนื่องจากประชาชนส่วนใหญ่ให้ความสนใจในการค้นหาคำว่า “เราไม่ทิ้งกัน” มากที่สุดในช่วงเวลาดังกล่าว แต่ภายหลังที่มาตรการเยียวยาสิ้นสุดลง กอรปกับสถานการณ์ทางเศรษฐกิจที่ชะลอตัวลง ภาคธุรกิจได้รับผลกระทบมากขึ้น ประชาชนจึงให้ความสนใจในการค้นหาคำว่า “สมัครงาน”และ “หางาน” มากยิ่งขึ้น ถึงแม้ว่าแบบจำลองกำลังสองน้อยที่สุดประมาณการอัตราการว่างงานไตรมาสที่สอง 2563 ที่ร้อยละ 1.0 ต่ำกว่าอัตราการว่างงานไตรมาสที่สองที่สำนักงานสถิติแห่งชาติเผยแพร่ที่ร้อยละ 2.0 หรือมีผู้ว่างงานจำนวน 7.45 แสนคนจากจำนวนแรงงาน 38.17 ล้านคน และมีผู้มีงานทำซึ่งขณะนี้ไม่ได้ทำงานและไม่ได้รับเงินเดือน แต่มีงานที่จะกลับไปทำจำนวน 2.08 ล้านคนแต่การมีข้อมูลเบื้องต้นที่มีความถี่เป็นรายเดือน ก็มีส่วนช่วยให้ติดตามภาวะเศรษฐกิจได้อย่างทันท่วงที อย่างไรก็ดี ดัชนีปริมาณความถี่ในการค้นหาจาก Google Trends สร้างจากกลุ่มตัวอย่างในฐานข้อมูลมิได้มาจาก ข้อมูลการค้นหาทั้งหมด และการเปลี่ยนแปลงของประมาณความถี่ในการค้นหา อาจเกิดได้จากหลายสาเหตุ นอกเหนือจาก ปัจจัยทางเศรษฐกิจ อาทิ การเปลี่ยนแปลงนโยบาย เป็นต้น ดังนั้น การนำข้อมูลปริมาณการค้นหาจาก Google Trends มาใช้จึงต้องมีความระมัดระวังในการคัดเลือกคำค้นหา อย่างไรก็ดี แม้ว่าข้อมูลจาก Google Trends จะยังคงมีข้อจำกัด แต่ก็มีประโยชน์ในการติดตามภาวะเศรษฐกิจ ร่วมกับข้อมูลเครื่องชี้แรงงานอื่น ๆ เช่น ข้อมูลผู้ประกันตน มาตรา 33 ข้อมูลผู้รับผลประโยชน์ทดแทนกรณีว่างงาน ของสำนักงานประกันสังคม ข้อมูลการสมัครงาน การบรรจุงาน และตำแหน่งงานว่างของกรมการจัดหางาน เป็นต้น เนื่องจากเป็นเครื่องชี้ที่มีความถี่สูงและมีความล่าช้าประมาณ 3-4 วัน
บรรณานุกรม
ภาษาไทย
กชพรรณ สัลเลขนันท์. (2019) จับชีพจร E-COMMERCE ด้วยข้อมูล GOOLGLE SEARCH. นำมาจาก https://www.bot.or.th/Thai/MonetaryPolicy/ArticleAndResearch/FAQ/FAQ_160.pdf
ปภัสสร แสวงสุขสันต์. (2018). การติดตามภาวะเศรษฐกิจด้วยข้อมูลปริมาณการ Search จาก Google. นำมาจาก https://www.bot.or.th/Thai/MonetaryPolicy/ArticleAndResearch/FAQ /FAQ_125.pdf.
ภาษาอังกฤษ
Choi, H & Varian, H. (2009). Predicting the Present with Google Trends. Retrieved from https://static.googleusercontent.com/media/www.google.com/th//googleblogs/pdfs/goog le_predicting_the_present.pdf.
Dickey, D. A. & Fuller, W. A. (1979). Distribution of the Estimators for Autoregressive Time Series with a Unit Root. Journal of the American Statistical Association, 74 (366), 427-431.
Dickey, D. A. & Fuller, W. A. (1981). The Likelihood Ratio Statistics for Autoregressive Time Series with a Unit Root. Econometrica, 49 (4), 1057-1072.
McLaren, N. & Rachana, S. (2011). Using Internet Search Data as Economic Indicators. Bank of England Quarterly Bulletin No. 2011 Q2.
Narita, F. & Yin, R. (2018). In Search of Information: Use of Google Trends’ Data to Narrow Information Gaps for Low-income Developing Countries. IMF Working Paper WP/18/286.
Popescu. M. (2015). Construction of Economic Indicators Using Internet Searches. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2679256
Vosen, S. and Schmidt, T. (2011). Forecasting Private Consumption: Survey‐based Indicators vs. Google Trends. Journal of Forecasting,Vol. 30 (6), 565-578.
Webb, K. (2009). Internet Search Statistics as a Source of Business Intelligence: Searches on Foreclosure as an Estimate of Actual Home Foreclosures. SJSU ScholarWorks.

