
บทความโดย[1]
ธนัตถ์พราว ลีลารัตน์
ผศ.ดร. ณัฐพงษ์ พัฒนพงษ์
และผศ.ดร. วศิน ศิวสฤษดิ์
การว่างงานนั้นถือเป็นประเด็นหนึ่งที่ผู้คนในสังคมต่างให้ความสนใจ เพราะเกี่ยวข้องโดยตรงกับความเป็นอยู่ของประชาชนและสถานะของเศรษฐกิจมหภาค จึงไม่น่าแปลกใจที่ว่าการว่างงานมักถูกหยิบยกมาเป็นประเด็นในด้านอื่นๆ ด้วยเช่นกัน ดังเช่นใน มิติด้านการเมือง สังคม การศึกษา ฯลฯ ซึ่งแสดงให้เห็นว่า การว่างงานนั้นอาจเกิดขึ้นได้จากหลายสาเหตุ และผลกระทบจากการว่างงานนั้นก็ทำให้เกิดผลสืบเนื่องเป็นวงกว้าง ดังนั้นการว่างงานจึงเป็นประเด็นสำคัญประเด็นหนึ่งที่ประเทศต่าง ๆ ทั่วโลกต่างให้ความสนใจและต้องการศึกษารวมทั้งทำความเข้าใจในประเด็นนี้ให้มากยิ่งขึ้น
ด้วยเหตุนี้เองจึงมีความร่วมมือกันในระดับนานาชาติผ่านองค์การแรงงานระหว่างประเทศ (International Labor Organization หรือ ILO) และองค์การสหประชาชาติ (United Nations หรือ UN) ในการศึกษาและกำหนดเกณฑ์การวัดการว่างงานของแต่ละประเทศให้เป็นมาตรฐานเดียวกัน โดยใช้อัตราการว่างงาน (Unemployment Rate) เป็นเครื่องชี้วัด เพื่อให้อัตราการว่างงานของแต่ละประเทศมีความสอดคล้องกัน และสามารถใช้วัดผลในเชิงเปรียบเทียบกันได้ นอกจากนี้อัตราการว่างงานยังสามารถนำมาใช้ประโยชน์ต่อยอดได้ในการพยากรณ์แนวโน้มหรือตัวเลขการว่างงานสำหรับวางแผนรับมือ หรือลดผลกระทบที่อาจจะเกิดขึ้นในอนาคตได้อีกด้วย
การศึกษาและพยากรณ์การว่างงานไม่ว่าจะเป็นการศึกษาด้วยตัวเลขอัตราการว่างงานหรือตัวเลขอื่นๆ ถูกนำมาศึกษาอย่างกว้างขวางด้วยแบบจำลองและตัวแปรที่หลากหลาย โดยมีจุดประสงค์เพื่อพัฒนาองค์ความรู้และความสามารถในการพยากรณ์การว่างงานให้มีประสิทธิภาพและมีความเหมาะสมขึ้นตามยุคสมัยที่เปลี่ยนไป จากการศึกษางานวิจัยในระยะหลังพบว่า มีการนำข้อมูลจากอินเทอร์เน็ตมาใช้ศึกษาและพยากรณ์การว่างงานมากยิ่งขึ้น[2],[3] เนื่องจากข้อมูลที่เกิดขึ้นบนอินเทอร์เน็ตนั้นมีความรวดเร็วและทันต่อเหตุการณ์มากกว่าข้อมูลออฟไลน์ในแบบเดิม อีกทั้งจำนวนผู้ใช้งานอินเทอร์เน็ตทั่วโลกนั้นเพิ่มสูงขึ้นเรื่อยๆ จนครอบคลุมประชากรส่วนใหญ่ในหลายๆ ประเทศ เช่นเดียวกันกับประเทศไทยที่มีจำนวนผู้ใช้งานอินเทอร์เน็ตเพิ่มขึ้นอย่างต่อเนื่อง จนกระทั่งในปี พ.ศ. 2561 ผู้ใช้งานอินเทอร์เน็ตมีจำนวนสูงถึง 47.5 ล้านคน หรือคิดเป็นร้อยละ 71.5 ของประชากร[4] ส่งผลให้การนำข้อมูลต่าง ๆ บนอินเทอร์เน็ตมาใช้ศึกษาและพยากรณ์การว่างงานเริ่มเป็นที่สนใจเช่นเดียวกัน[5],[6] อย่างไรก็ตาม การใช้ข้อมูลออฟไลน์ในแบบเดิมมาพยากรณ์การว่างงานนั้นยังคงน่าสนใจอยู่ไม่น้อย และผู้ศึกษาวิจัยคงไม่อาจมองข้ามข้อมูลเหล่านี้ไปได้ เนื่องจากข้อมูลที่ได้มีการระบุแหล่งที่มาและวิธีการประมวลผลข้อมูลได้อย่างชัดเจน ทำให้ข้อมูลที่ได้มีความน่าเชื่อถือสูงกว่าข้อมูลจากอินเทอร์เน็ต ดังนั้นจึงเป็นความท้าทายของการศึกษาวิจัยในยุคปัจจุบันที่จะต้องผสมผสานข้อมูลในแบบเดิมกับข้อมูลจากอินเทอร์เน็ตเข้าด้วยกันเพื่อพัฒนาประสิทธิภาพในการศึกษาและพยากรณ์การว่างงานให้มีความรวดเร็ว ทันเหตุการณ์ ถูกต้อง และน่าเชื่อถือไปพร้อมๆ กัน
ในบทความนี้จะเล่าถึงการศึกษาการนำข้อมูลทั้งแบบออฟไลน์และข้อมูลจากอินเทอร์เน็ตที่ได้รับความนิยมในการศึกษาวิจัยอย่าง Google Trends และ Twitter มาใช้ร่วมกันในการพยากรณ์อัตราการว่างงานไทย โดยจะแบ่งออกเป็น 6 ส่วน ในส่วนที่ 1 จะเป็นการเกริ่นให้ผู้อ่านเข้าใจถึงอัตราการว่างงานไทย จากนั้นในส่วนที่ 2 จะเป็นการเล่าถึงข้อมูลจากอินเทอร์เน็ตทั้งจาก Google Trends และ Twitter ที่นำมาใช้ในการศึกษานี้ ต่อมาในส่วนที่ 3 จะพูดถึงการหาความสัมพันธ์กันระหว่างข้อมูลอัตราการว่างงาน ข้อมูล Google Trends และ Twitter ก่อนนำมาใช้ร่วมกันในการพยากรณ์ ในส่วนที่ 4 จะกล่าวถึงการพยากรณ์อัตราการว่างงานโดยใช้ข้อมูล Google Trends และ Twitter ร่วมด้วย หลังจากนั้นในส่วนที่ 5 จะเป็นการอภิปรายถึงผลการพยากรณ์ และส่วนสุดท้าย (ส่วนที่ 6) จะกล่าวถึงข้อสรุปและข้อเสนอแนะเชิงนโยบาย
[1] บทความนี้เป็นผลสืบเนื่องจากการค้นคว้าอิสระในหลักสูตรปริญญาโทเศรษฐศาสตร์ธุรกิจ(MBE) คณะเศรษฐศาสตร์ มหาวิทยาลัยธรรมศาสตร์
[2] บทความวิจัยโดย McLaren and Shanbhogue (2011) ได้ศึกษาการค้นหาข้อมูลที่เกี่ยวข้องกับตลาดแรงงานและที่อยู่อาศัยของสหราชอาณาจักร (United Kingdom) บนอินเทอร์เน็ตผ่านเว็บไซต์ Google ด้วย Google Insights
[3] บทความวิจัยโดย Antenucci et al. (2014) ได้ศึกษาการนำข้อมูลจาก Twitter มาสร้างเป็นดัชนี “Job Loss”, “Job Search” และ “Job Posting” โดยการนับความถี่ของกลุ่มคำที่เกี่ยวข้องกับข้อความในดัชนีนั้นๆ เพื่อนำดัชนีที่ได้มาสร้างแบบจำลองและเปรียบเทียบกับข้อมูลจากการสำรวจโดยหน่วยงานภาครัฐ
[4] จากรายงานผลการสำรวจพฤติกรรมผู้ใช้อินเทอร์เน็ตในประเทศไทย ปี พ.ศ. 2562 ซึ่งจัดทำโดยสำนักงานพัฒนาธุรกรรมทางธุรกิจ กระทรวงดิจิทัลเพื่อเศรษฐกิจและสังคม
[5] บทความวิจัยโดย Nakavachara and Lekfuangfu (2018) ได้ศึกษาการใช้ Google Trends คาดการณ์เครื่องมือชี้วัดทางเศรษฐกิจในด้านการว่างงาน รวมทั้งด้านอื่นๆ แบบทันกาล (nowcasting)
[6] Sawaengsuksant (2018) ได้ศึกษาการติดตามภาวะเศรษฐกิจด้วยข้อมูลปริมาณการค้นหาจาก Google และได้นำผลการวิเคราะห์จาก Google Correlate และ Google Trends มาพัฒนาเครื่องชี้เศรษฐกิจในด้านต่างๆ รวมทั้งเครื่องชี้จำนวนผู้ว่างงาน (Unemployed Persons) ด้วย
1.ทำความเข้าใจกับอัตราการว่างงานไทย
อัตราการว่างงานไทยนั้น เป็นข้อมูลที่บ่งบอกถึงร้อยละของผู้ว่างงานต่อกำลังแรงงานรวมทั้งหมดของประเทศ โดยในแต่ละเดือนสำนักงานสถิติแห่งชาติจะทำการสำรวจภาวะการทำงานของประชากรตามข้อเสนอแนะของ ILO และ UN เพื่อให้ได้ข้อมูลเหล่านี้มา รวมถึงตัวเลขอื่นๆ ที่เกี่ยวข้องกับการทำงาน การว่างงาน การประกอบกิจกรรมต่างๆ ของประชากรในประเทศด้วย ซึ่งผู้ว่างงานตามการสำรวจนี้จะหมายถึง บุคคลที่มีอายุ 15 ปีขึ้นไปที่พร้อมจะทำงานในสัปดาห์ที่มีการสำรวจ หรือบุคคลที่ในช่วง 30 วันที่ผ่านมาได้มีการหางาน สมัครงานหรือรอบรรจุ แต่ยังไม่ได้ทำงานและไม่มีงานประจำ ส่วนกำลังแรงงานรวมนั้นจะหมายถึง บุคคลที่มีอายุ 15 ปีขึ้นไปซึ่งอาจจะมีงานทำ ว่างงาน หรือรอฤดูกาลที่เหมาะสมเพื่อที่จะทำงานอยู่
ในปัจจุบันข้อมูลอัตราการว่างงานนี้ถือเป็นเครื่องชี้วัดหนึ่งในด้านแรงงานที่มีความสำคัญต่อเศรษฐกิจของประเทศเป็นอย่างมาก โดยสะท้อนให้เห็นว่า ประเทศไทยเป็นประเทศที่มีอัตราการว่างงานที่ต่ำ (ค่าเฉลี่ย 8 ปีย้อนหลัง ระหว่างปี พ.ศ. 2554 ถึงปี พ.ศ. 2561 อยู่ที่ร้อยละ 0.88) และมีลักษณะการมีงานทำต่ำกว่าระดับ(Underemployment) หรืออาจกล่าวได้ว่า ผู้ที่มีงานทำนั้นทำงานได้ไม่เต็มขีดความสามารถที่มี แต่ก็เป็นที่น่าสังเกตว่าในระยะหลังตัวเลขอัตราการว่างงานไทยนั้นเริ่มมีแนวโน้มสูงขึ้น และสูงกว่าค่าเฉลี่ยช่วงปี พ.ศ. 2554 – 2561 ดังแสดงในภาพที่ 1
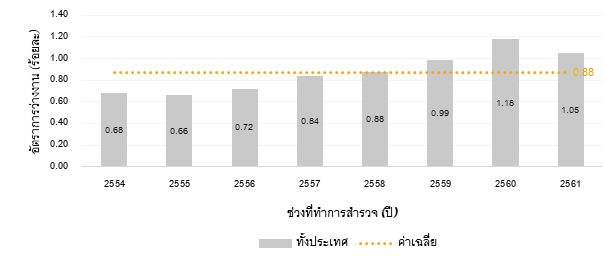
ที่มา: รวบรวมข้อมูลจาก https://www.bot.or.th/App/BIZSHR/stat/DataSeries/30
2. การศึกษาวิจัยวิถีใหม่โดยใช้ข้อมูลจาก Google Trends และ Twitter
Google Trends เป็นเครื่องมือหนึ่งที่สามารถใช้วิเคราะห์แนวโน้มและระดับความสนใจของข้อความต่างๆ ที่มีการค้นหาผ่านเว็บไซต์ Google เมื่อเทียบกับจุดสูงสุดในช่วงเวลาที่ระบุ (สามารถระบุช่วงเวลาย้อนหลังได้ถึงปี พ.ศ. 2547) ซึ่งมีค่าตั้งแต่ 0 ถึง 100 โดย 100 หมายถึง ระดับความสนใจสูงสุด สำหรับการนำข้อมูลที่มีการค้นหาในประเทศไทยมาใช้งานก็สามารถทำได้โดยสะดวก โดยสามารถใช้งานเว็บไซต์ https://trends.google.co.th/trends/?geo=TH และพิมพ์ข้อความที่สนใจ ก็สามารถทราบผลลัพธ์หรือดาวน์โหลดข้อมูลไปใช้งานต่อได้ทันทีโดยไม่มีค่าใช้จ่ายใด ๆ
ในปัจจุบันมีการนำข้อมูลจาก Google Trends มาประยุกต์ใช้งานในหลายๆ ด้าน โดยเฉพาะในด้านการตลาดที่มีการนำข้อมูลนี้มาวิเคราะห์พฤติกรรมผู้บริโภคเพื่อช่วยคาดการณ์ยอดขายหรือเพิ่มยอดขายให้มากยิ่งขึ้น ในส่วนของการศึกษาวิจัยก็มีการใช้ข้อมูลจาก Google Trends เช่นกัน โดยจะใช้ในการศึกษาพฤติกรรมร่วมกับหรือทดแทนข้อมูลการสำรวจในแบบเดิม เพื่อช่วยให้การวิเคราะห์ข้อมูลมีความรวดเร็วและถูกต้องมากยิ่งขึ้น
ที่มา: https://trends.google.co.th/trends/?geo=TH
Twitter เป็นบริการเครือข่ายสังคมออนไลน์จำพวก Microblog ที่เน้นการติดต่อสื่อสาร หรือการแสดงความคิดเห็นผ่านข้อความที่สั้น กระชับ ได้ใจความ รวดเร็ว และทันต่อเหตุการณ์ ด้วยเหตุนี้ทำให้ Twitter ได้รับความนิยมและมีผู้ใช้เป็นจำนวนมากจากทั้งในและต่างประเทศ แต่อย่างไรก็ตามการจะนำข้อมูลจาก Twitter มาใช้งานนั้นมีความซับซ้อนมากกว่าข้อมูลจาก Google Trends เนื่องจากไม่สามารถดึงข้อมูลจากเว็บไซต์ได้โดยตรง ต้องมีการสมัครสมาชิกและสมัครบริการ Application Programming Interface (API) ของ Twitter ก่อน (อาจมีค่าใช้จ่ายในการสมัครบริการ API โดยขึ้นอยู่กับระยะเวลาและปริมาณข้อมูลที่ต้องการ) อีกทั้งต้องอาศัยความเข้าใจในด้านเทคนิคการดึงข้อมูลผ่าน API ด้วยจึงจะสามารถดึงข้อมูลมาใช้งานได้ ซึ่งหากสนใจในรายละเอียดสามารถศึกษาเพิ่มเติมได้ที่ https://developer.twitter.com/en/docs
ที่มา: https://developer.twitter.com/en/docs
จากการศึกษาข้อมูลจากทั้ง Google Trends และ Twitter ทำให้เห็นถึงประโยชน์และความเป็นไปได้ในการใช้ข้อมูลจากทั้ง 2 แหล่งมาศึกษาร่วมกับข้อมูลอัตราการว่างงาน ในการศึกษานี้จึงได้นำข้อมูลทั้งหมดมาศึกษาร่วมกันเป็นรายเดือน โดยใช้ข้อมูลตั้งแต่เดือนมกราคม ปี พ.ศ. 2557 ไปจนถึงเดือนธันวาคม ปี พ.ศ. 2562 (72 ข้อมูล) เนื่องจากระยะเวลาดังกล่าวมีจำนวนผู้ใช้งานอินเทอร์เน็ตในประเทศไทยที่ครอบคลุมเพียงพอในการศึกษาและจำนวนข้อมูลที่ศึกษาก็มีความเหมาะสมเพียงพอสำหรับการพยากรณ์ข้อมูล
ในส่วนของการรวบรวมข้อมูลนั้น ข้อมูลอัตราการว่างงานจะใช้ข้อมูลจากเว็บไซต์ธนาคารแห่งประเทศไทยซึ่งได้นำข้อมูลมาจากสำนักงานสถิติแห่งชาติ เนื่องจากมีความสะดวกในการเข้าถึงข้อมูลมากกว่าการรวบรวมข้อมูลจากเว็บไซต์ของสำนักงานสถิติแห่งชาติโดยตรง ส่วนข้อมูลจากอินเทอร์เน็ตทั้งจาก Google Trends และ Twitter จะมีการรวบรวมข้อมูลคำที่เกี่ยวข้องกับอัตราการว่างงานทั้งหมด 6 คำ ประกอบด้วยคำว่า “หางาน” “สมัครงาน” “ว่างงาน” “สัมภาษณ์งาน” “ประกันสังคม” “เงินทดแทน”[7] ทำให้ข้อมูลที่ใช้ในการศึกษาครั้งนี้มีทั้งหมด 13 ชุด ประกอบด้วย ข้อมูลอัตราการว่างงาน 1 ชุด ข้อมูลระดับความสนใจของคำที่เกี่ยวข้องกับอัตราการว่างงานจาก Google Trends 6 ชุด และข้อมูลร้อยละของจำนวน Tweet ที่มีคำที่เกี่ยวข้องกับอัตราการว่างงานต่อจำนวน Tweet ทั้งหมดจาก Twitter 6 ชุด
[7] สำหรับการรวบรวมข้อมูลจาก Google Trends นั้นจะรวบรวมข้อมูลระดับความสนใจโดยตรงจากเว็บไซต์ ส่วนการรวบรวมข้อมูลจาก Twitter จะใช้ชุดคำสั่ง (Code) ที่ผู้วิจัยพัฒนาขึ้นด้วยภาษา Python และใช้ไลบรารีที่ชื่อว่า “searchtweets” ร่วมด้วยในการดึงข้อมูลผ่านบริการ Search API ของ Twitter แบบ “Count Endpoint” โดยกำหนดค่า Bucket ให้เป็น Day ทำให้ได้ข้อมูลจำนวน Tweet ที่มีคำที่เกี่ยวข้องกับอัตราการว่างงานทั้ง 6 คำ และจำนวน Tweet ทั้งหมดในแต่ละวันตามเวลามาตรฐานโลก (UTC) จากนั้นจึงนำข้อมูลรายวันที่ได้มารวมกันเป็นข้อมูลรายเดือน และคำนวณเป็นร้อยละของจำนวน Tweet ที่มีคำที่เกี่ยวข้องกับอัตราการว่างงานต่อจำนวน Tweet ทั้งหมดในแต่ละเดือน เพื่อใช้ในการศึกษานี้
3. การหาความสัมพันธ์และการนำข้อมูลอัตราการว่างงาน ข้อมูลจาก Google Trends และ Twitter มาใช้ร่วมกัน
หลังจากรวบรวมข้อมูลที่สนใจศึกษาได้ครบถ้วนแล้ว ในขั้นตอนต่อมาจะเป็นการนำข้อมูลเหล่านี้มาวิเคราะห์หาความสัมพันธ์ระหว่างกันโดยใช้ค่าสหสัมพันธ์แบบเพียร์สัน (Pearson correlation coefficient) เพื่อให้แน่ใจว่าข้อมูลจากอินเทอร์เน็ตทั้ง 2 แหล่งนั้นมีความสัมพันธ์หรือมีความเกี่ยวข้องกับอัตราการว่างงานจริง ก่อนนำไปศึกษาในขั้นตอนต่อไป โดยค่าสหสัมพันธ์นี้จะเป็นค่าที่แสดงระดับความสัมพันธ์ระหว่างกัน หากค่าที่ได้เป็นค่าบวกแสดงว่าข้อมูลมีความสัมพันธ์ไปในทิศทางเดียวกัน แต่ถ้าค่าที่ได้เป็นลบแสดงว่าข้อมูลมีความสัมพันธ์ไปในทิศทางตรงกันข้ามกัน ส่วนตัวเลขที่ปรากฏหากมีค่าเข้าใกล้ 1 หรือ -1 แสดงว่าข้อมูลมีความสัมพันธ์กันมาก และในทางกลับกัน หากตัวเลขที่ปรากฏมีค่าเข้าใกล้ 0 แสดงว่าข้อมูลนั้นมีความสัมพันธ์กันน้อยมากหรืออาจไม่มีความสัมพันธ์ระหว่างกัน ซึ่งผลลัพธ์จากการศึกษาในขั้นตอนนี้ แสดงได้ดังตารางที่ 1
| คำว่า | ค่าสหสัมพันธ์ระหว่าง อัตราการว่างงาน กับ Google Trends | ค่าสหสัมพันธ์ระหว่าง อัตราการว่างงาน กับ |
|---|---|---|
| หางาน | 0.2282 | 0.1829 |
| สัมภาษณ์งาน | 0.3222* | 0.2349* |
| สมัครงาน | 0.1282 | -0.0377 |
| ประกันสังคม | 0.2884* | -0.0777 |
| เงินทดแทน | 0.0945 | 0.0725 |
| ว่างงาน | 0.4680* | -0.0554 |
หมายเหตุ. จากการคำนวณด้วยโปรแกรม Stata โดยผู้ศึกษา
* แสดงถึงมีนัยสำคัญทางสถิติที่ระดับ 0.05
จากตารางแสดงให้เห็นว่า ข้อมูลจาก Google Trends คำว่า “ว่างงาน” มีค่าสหสัมพันธ์กับข้อมูลอัตราการว่างงานสูงสุดที่ 0.4680 ที่ระดับนัยสำคัญ 0.05 ส่วนข้อมูลจาก Twitter คำว่า “สัมภาษณ์งาน” มีค่าสหสัมพันธ์กับข้อมูลอัตราการว่างงานสูงสุดที่ 0.2349 ที่ระดับนัยสำคัญ 0.05 และในตารางนี้ยังแสดงให้เห็นอีกว่าค่าสหสัมพันธ์ที่ได้ส่วนใหญ่มีค่าเป็นบวก มีเพียง 3 ค่าจาก Twitter เท่านั้นที่แสดงค่าเป็นลบ อีกทั้งค่าสหสัมพันธ์ระหว่างอัตราการว่างงานกับข้อมูลจาก Google Trends นั้นมีค่ามากกว่าข้อมูลจาก Twitter ทุกค่า
นอกจากนี้เมื่อพิจารณาเพิ่มเติมถึงช่วงเวลาที่ต่างกัน (lag) ทั้งก่อนและหลัง 1 ช่วงเวลาว่ามีผลต่อความสัมพันธ์ระหว่างกันของข้อมูลทั้ง 3 ข้อมูลหรือไม่ โดยได้นำคำที่มีค่าสหสัมพันธ์สูงสุด คือ คำว่า “ว่างงาน” สำหรับข้อมูลจาก Google Trends และคำว่า “สัมภาษณ์งาน” สำหรับข้อมูลจาก Twitter มาพิจารณา ได้ผลการศึกษาดังตารางที่ 2
| Lag | ค่าสหสัมพันธ์ระหว่าง อัตราการว่างงาน กับ Google Trends | ค่าสหสัมพันธ์ระหว่าง อัตราการว่างงาน กับ |
|---|---|---|
| -1 | 0.4276 | 0.3046 |
| 0 | 0.4680 | 0.2349 |
| 1 | 0.4708 | 0.3124 |
หมายเหตุ. จากการคำนวณด้วยโปรแกรม Stata โดยผู้ศึกษา
จากผลการศึกษาพบว่า ค่าสหสัมพันธ์ระหว่างข้อมูลอัตราการว่างงานกับข้อมูลจาก Google Trends และ Twitter มีค่ามากที่สุดที่ lag ที่ 1 แสดงให้เห็นว่าข้อมูลจาก Google Trends และ Twitter อาจมีลักษณะเป็นตัวชี้วัดตาม (Lagging Indicator)
อย่างไรก็ตาม การวัดความสัมพันธ์ระหว่างกันของข้อมูลนั้นเป็นการวัดผลเพียงเบื้องต้น เพื่อประเมินว่าข้อมูลมีความน่าสนใจในการนำไปใช้ประโยชน์ต่อไปเพียงใด ซึ่งผลระดับความสัมพันธ์ที่ได้นั้นระบุถึงนัยทางสถิติที่มีระดับความสำคัญและสอดคล้องกับทิศทางของสถานการณ์ปัจจุบัน แต่การวัดผลเพียงแค่นี้ยังไม่เพียงพอสำหรับการนำไปใช้ในการพยากรณ์ เนื่องจากข้อมูลที่ใช้ในการศึกษาทั้งหมดมีลักษณะเป็นข้อมูลอนุกรมเวลา (Time Series Data) จึงต้องมีการทดสอบเพิ่มเติมด้วยวิธี Augmented Dickey-Fuller (ADF) และพิจารณารูปแบบกราฟ Correlogram ซึ่งปรากฏว่า ข้อมูลมีความไม่นิ่ง (Non-stationary) และมีความผันแปรจากฤดูกาล (Seasonal Variation) อยู่ ดังนั้นในการศึกษานี้จึงจำเป็นต้องปรับรูปแบบข้อมูลทั้งหมด โดยได้เลือกใช้วิธีหาผลต่างอันดับที่ 1 และ 12 ในการแปลงข้อมูล ทำให้จำนวนข้อมูลในแต่ละชุดข้อมูลมีเพียง 59 ข้อมูล จากนั้นจึงนำข้อมูลที่ได้มาตรวจสอบความสัมพันธ์และใช้งานในการพยากรณ์ต่อไป โดยค่าสหสัมพันธ์ดังแสดงในตารางที่ 3
| คำว่า | ค่าสหสัมพันธ์ระหว่าง อัตราการว่างงาน กับ Google Trends | ค่าสหสัมพันธ์ระหว่าง อัตราการว่างงาน กับ |
|---|---|---|
| หางาน | 0.0947 | 0.1946 |
| สัมภาษณ์งาน | -0.1027 | -0.2166 |
| สมัครงาน | 0.1120 | -0.3531* |
| ประกันสังคม | 0.2050 | -0.0921 |
| เงินทดแทน | 0.4205* | 0.2222 |
| ว่างงาน | -0.1096 | -0.1449 |
หมายเหตุ. จากการคำนวณด้วยโปรแกรม Stata โดยผู้ศึกษา
* แสดงถึงมีนัยสำคัญทางสถิติที่ระดับ 0.05
จากตารางแสดงให้เห็นว่า คำว่า “เงินทดแทน” มีค่าสหสัมพันธ์ระหว่างข้อมูล Google Trends กับอัตราการว่างงานสูงสุดที่ 0.4205 ที่ระดับนัยสำคัญ 0.05 ส่วนข้อมูลจาก Twitter คำว่า “สมัครงาน” มีค่าสหสัมพันธ์กับข้อมูลอัตราการว่างงานสูงสุดที่ -0.3531 ที่ระดับนัยสำคัญ 0.05 ซึ่งแตกต่างไปจากผลการใช้ค่าจริงในการหาค่าสหสัมพันธ์ จึงมีความเป็นไปได้ว่าข้อมูลจริงนั้นมีความสัมพันธ์กับเวลา หรือมีความสัมพันธ์ปลอม (Spurious Relationship) อยู่ หากนำข้อมูลเหล่านี้ไปใช้พยากรณ์ต่ออาจส่งผลให้เกิดความคลาดเคลื่อนสูง
4. การพยากรณ์อัตราการว่างงานโดยใช้ข้อมูลจาก Google Trends และ Twitter ร่วมด้วย
ในการพยากรณ์อัตราการว่างงานนั้น โดยปกติแล้วสามารถทำได้หลายรูปแบบ และตัวแปรที่ใช้ก็สามารถเลือกใช้ได้อย่างหลากหลายตามความเหมาะสม แต่เนื่องจากในการศึกษานี้ต้องการผสมผสานข้อมูลในแบบเดิมกับข้อมูลจากอินเทอร์เน็ตเข้าด้วยกันเพื่อพัฒนาประสิทธิภาพในการศึกษาและพยากรณ์การว่างงาน จึงได้เลือกใช้ข้อมูลที่ผ่านการแปลงแล้วจาก Google Trends และ Twitter ที่มีค่าสหสัมพันธ์กับข้อมูลอัตราการว่างงานสูงที่สุด ซึ่งก็คือข้อมูลจาก Google Trends คำว่า “เงินทดแทน” และข้อมูลจาก Twitter คำว่า “สมัครงาน” มาใช้ร่วมกับข้อมูลอัตราการว่างงานในอดีตในการพยากรณ์อัตราการว่างงานในปัจจุบัน โดยแบ่งเป็น 3 แบบจำลองด้วยกัน ประกอบด้วย
1) แบบจำลองที่ใช้เพียงข้อมูลอัตราการว่างงานในอดีต
2) แบบจำลองที่ใช้ข้อมูลอัตราการว่างงานในอดีตร่วมกับข้อมูลจาก Google Trends ในปัจจุบัน
3) แบบจำลองที่ใช้ข้อมูลอัตราการว่างงานในอดีตร่วมกับข้อมูลจาก Twitter ในปัจจุบัน
โดยในแบบจำลอง 1) จะใช้ตัวแบบ Auto Regressive Integrated Moving Average (ARIMA) ในการพยากรณ์ ส่วนแบบจำลอง 2) และ 3) จะใช้ Auto Regressive Integrated Moving Average with Explanatory Variable (ARIMAX) เป็นตัวแบบในการพยากรณ์ เนื่องจากมีตัวแปรภายนอก (ข้อมูลจาก Google Trends และ Twitter) เข้ามาเกี่ยวข้องด้วย
หลังจากได้แบบจำลองเรียบร้อยแล้ว ขั้นตอนต่อมาจะเป็นการเลือกตัวแบบที่เหมาะสม[8] และพยากรณ์ตามตัวแบบที่เหมาะสมของแต่ละแบบจำลอง ซึ่งในขั้นตอนนี้จะเริ่มจากการแบ่งข้อมูลที่ใช้ทั้งหมด 59 ข้อมูลออกเป็น 2 ส่วนก่อน โดยส่วนแรกซึ่งมีสัดส่วนประมาณร้อยละ 80 ของข้อมูลทั้งหมดหรือ 47 ข้อมูล คือ ข้อมูลที่ใช้ในการสร้างตัวแบบพยากรณ์ (In-Sample) และในส่วนที่ 2 คือข้อมูลส่วนที่ต้องการพยากรณ์เทียบกับค่าจริง (Out-of-Sample) ซึ่งมีสัดส่วนประมาณร้อยละ 20 ของข้อมูลทั้งหมดหรือ 12 ข้อมูล จากนั้นจึงนำข้อมูล In-Sample 47 ข้อมูล มาใช้เลือกตัวแบบที่เหมาะสมและพยากรณ์ Out-of-Sample โดยเริ่มจากการนำข้อมูลที่ 1 ถึง 47 มาใช้เลือกตัวแบบที่เหมาะสมและพยากรณ์ข้อมูลที่ 48 จากนั้นจึงปรับข้อมูล In-sample และ Out-of-Sample ต่อไปเป็นข้อมูลที่ 2 ถึง 48 มาใช้เลือกตัวแบบที่เหมาะสมและพยากรณ์ข้อมูลที่ 49 และขยับข้อมูลทีละข้อมูลต่อไปเรื่อย ๆ จนครบทุกข้อมูลและทุกแบบจำลอง[9]
จากนั้นนำผลการพยากรณ์ที่ได้จากทั้ง 3 แบบจำลองมาประเมินศักยภาพในการพยากรณ์ข้อมูล Out-of-Sample ทั้ง 12 ข้อมูล ด้วยค่าสหสัมพันธ์และค่าคลาดเคลื่อนกำลังสองเฉลี่ย (Root Mean Squared Error หรือ RMSE)
[8] ใช้ค่า Akaike Information Criterion (AIC) ต่ำสุดเป็นเกณฑ์
[9] ในขั้นตอนนี้ ผู้วิจัยคำนวณโดยการเขียนชุดคำสั่ง (Code) ในโปรแกรม EViews
5. ผลลัพธ์ที่ได้จากการพยากรณ์และการวัดผล
ผลการพยากรณ์ข้อมูล Out-of-Sample จากทั้ง 3 แบบจำลอง เมื่อเทียบกับค่าผลต่างลำดับที่ 1 และ 12 ของอัตราการว่างงานจริงแสดงได้ดังภาพที่ 4 โดย
ค่าผลต่างลำดับที่ 1 และ 12 ของอัตราการว่างงานจริง แทนด้วย เส้นกราฟสีส้ม (DD12UNEMP_ALL)
ผลการพยากรณ์ด้วยแบบจำลอง 1) แทนด้วย เส้นกราฟสีเขียว (DD12UNEMP_ALL_F_UNEMP)
ผลการพยากรณ์ด้วยแบบจำลอง 2) แทนด้วย เส้นกราฟสีแดง (DD12UNEMP_ALL_F_GG)
ผลการพยากรณ์ด้วยแบบจำลอง 3) แทนด้วย เส้นกราฟสีฟ้า (DD12UNEMP_ALL_F_TW)
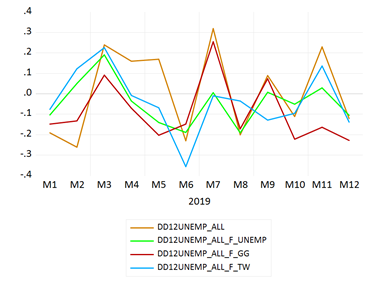
เทียบกับค่าที่ได้จากการพยากรณ์ทุกแบบจำลอง
ที่มา : จากการสรุปของผู้ศึกษา
จากการพิจารณากราฟค่าผลต่างลำดับที่ 1 และ 12 ของอัตราการว่างงานจริงเทียบกับค่าที่ได้จากการพยากรณ์ทั้ง 3 แบบจำลอง พบว่า ค่าที่แบบจำลองทั้งสาม พยากรณ์ได้ในแต่ละช่วงเวลาจะมีระดับความคลาดเคลื่อนต่างกัน จึงไม่สามารถสรุปได้ชัดเจนว่าแบบจำลองใดมีความเหมาะสมมากที่สุด ดังนั้นในการศึกษานี้จึงต้องใช้ค่าสหสัมพันธ์ และค่า RMSE เข้ามาช่วยในการประเมินศักยภาพในการพยากรณ์ของทั้ง 3 แบบจำลอง ซึ่งได้ผลดังตารางที่ 4
| แบบจำลอง | ค่าสหสัมพันธ์ | ค่า RMSE |
|---|---|---|
| แบบจำลอง 1) (ใช้ข้อมูลอัตราการว่างงานในอดีตพยากรณ์) | 0.528512 | 0.180626 |
| แบบจำลอง 2) (ใช้ข้อมูลปัจจุบันจาก Google Trends ในการพยากรณ์ด้วย) | 0.619802 | 0.187842 |
| แบบจำลอง 3) (ใช้ข้อมูลปัจจุบันจาก Twitter ในการพยากรณ์ด้วย) | 0.452781 | 0.194160 |
หมายเหตุ ใช้ข้อมูลตั้งแต่เดือน มกราคม ถึงเดือน ธันวาคม ปี พ.ศ. 2562 ในการคำนวณ
ผลการเปรียบเทียบนี้ แสดงให้เห็นถึงข้อจำกัดในปัจจุบันและศักยภาพในอนาคตสำหรับการนำข้อมูลจาก Google Trends และ Twitter ทั้งนี้ถึงแม้ว่าการเพิ่มข้อมูลจาก Google Trends ในการพยากรณ์ (แบบจำลอง 2)) จะทำให้ค่าสหสัมพันธ์ระหว่างผลการพยากรณ์กับข้อมูลจริงสูงขึ้น (ซึ่งสะท้อนถึงความสามารถในการชี้นำทิศทางได้สอดคล้องกับข้อมูลจริงมากขึ้น) แต่อย่างไรก็ดีเมื่อวิเคราะห์ความคลาดเคลื่อนในการพยากรณ์ด้วย RMSE พบว่าทั้งการเพิ่มข้อมูลจาก Google Trends และ Twitter เข้าไป (แบบจำลอง 2) และ 3)) ก็ยังไม่สามารถทำให้ความคลาดเคลื่อนลดลงจากการพยากรณ์ด้วยข้อมูลอัตราว่างงานเพียงข้อมูลเดียว
6. ข้อสรุปและข้อเสนอแนะเชิงนโยบาย
การศึกษาในครั้งนี้สามารถสรุปผลการศึกษาในด้านความสัมพันธ์ระหว่างอัตราการว่างงานของไทยกับข้อมูลจาก Google Trends และ Twitter ได้ว่า อัตราการว่างงานของไทยมีความสัมพันธ์กับข้อมูลจาก Google Trends มากกว่าข้อมูลจาก Twitter ทุกข้อมูล โดยข้อมูลจาก Google Trends ที่มีความสัมพันธ์กับอัตราการว่างงานมากที่สุด คือ คำว่า “ว่างงาน” ส่วนข้อมูลจาก Twitter คำว่า “สัมภาษณ์งาน” มีค่าสหสัมพันธ์มากที่สุด
ทั้งนี้ เมื่อพิจารณาถึงช่วงเวลาที่ต่างกัน (Lag) ทั้งก่อนและหลัง 1 ช่วงเวลาพบว่า ข้อมูลจาก Google Trends และ Twitter อาจมีลักษณะเป็นตัวชี้วัดตาม (Lagging Indicator) เมื่อแปลงข้อมูลทั้ง 3 ข้อมูลให้มีความนิ่งและไม่มีความผันแปรจากฤดูกาลพบว่า อัตราการว่างงานของไทยมีความสัมพันธ์กับข้อมูลจาก Google Trends คำว่า “เงินทดแทน” มากที่สุด และมีความสัมพันธ์กับข้อมูลจาก Twitter คำว่า “สมัครงาน” มากที่สุด
จากการนำข้อมูลที่เกี่ยวข้องจากทั้ง Google Trends และ Twitter ที่มีค่าสหสัมพันธ์สูงสุดกับอัตราการว่างงานมาใช้ประโยชน์ในการพยากรณ์อัตราการว่างงานสามารถสรุปผลการศึกษาได้ว่า แบบจำลองที่ใช้ข้อมูลที่เกี่ยวข้องจาก Google Trends (แบบจำลอง 2)) นั้น สามารถเพิ่มศักยภาพในการระบุทิศทางของการเปลี่ยนแปลงของอัตราว่างงานได้มากขึ้น แต่อย่างไรก็ดี เมื่อพิจารณาความแม่นยำด้วยค่า RMSE พบว่าทั้งการใช้ข้อมูลที่เกี่ยวข้องจาก Google Trends และข้อมูลที่เกี่ยวข้องจาก Twitter ยังไม่ได้ส่งผลให้การพยากรณ์มีความคลาดเคลื่อนลดน้อยลง ผลที่ได้นี้แสดงให้เห็นถึงทั้งศักยภาพในอนาคตและข้อจำกัดในปัจจุบัน ดังนั้นจึงควรส่งเสริมให้มีการพัฒนาอย่างต่อเนื่องในอนาคต โดยควรมีการพิจารณาถึงประเด็นในด้านต่าง ๆ ดังนี้
- ในด้านระยะเวลาการศึกษา เนื่องจากการค้นหาข้อมูลหรือแสดงความคิดเห็นบนอินเทอร์เน็ตนั้นเพิ่งได้รับความนิยมไม่นานนัก ทำให้การเลือกระยะเวลาการศึกษาที่ยาวนานเกินไปอาจส่งผลให้ข้อมูลบนอินเทอร์เน็ตที่ใช้นั้นไม่ครอบคลุมกลุ่มประชากรส่วนใหญ่ของประเทศได้ แต่การเลือกระยะเวลาที่สั้นไปก็อาจทำให้ข้อมูลมีความคลาดเคลื่อนสูงขึ้นได้ ดังนั้นการศึกษาในครั้งต่อไปควรพิจารณาระยะเวลาการศึกษาโดยคำนึงถึงปัจจัยที่กล่าวมานี้ รวมทั้งพิจารณาความถี่ของข้อมูลให้เหมาะสมกับการศึกษานั้นๆ ด้วย
- ในด้านข้อมูลที่ใช้ในการศึกษานั้น การใช้ข้อมูลจากอินเทอร์เน็ตโดยตรงอาจทำให้ข้อมูลที่ได้มีความคลาดเคลื่อนจากการทำซ้ำ รวมถึงการนำส่งข้อมูลจากผู้ใช้ที่ไม่เป็นไปตามข้อเท็จจริงอยู่ การนำข้อมูลเหล่านี้มาใช้ศึกษาในอนาคตจึงควรเพิ่มขั้นตอนการคัดกรองข้อมูล เพื่อให้ข้อมูลที่ได้สะท้อนความเป็นจริงมากยิ่งขึ้น รวมทั้งศึกษาและตรวจสอบวิธีการหรือข้อจำกัดในการดึงข้อมูลให้แน่ชัด และควรศึกษาแนวทางการปรับปรุงข้อมูลอัตราการว่างงานก่อนนำมาใช้ในการศึกษา เช่น การปรับลักษณะของการนิยาม “การเป็นผู้มีงานทำ” และ “การว่างงาน” ให้สอดคล้องกันระหว่างข้อมูลของสำนักงานสถิติแห่งชาติและลักษณะของความเข้าใจโดยทั่วไปของผู้ใช้งาน Google และ Twitter โดยเฉพาะอย่างยิ่งในกรณีของการเป็นผู้ทำงานไม่ถึงระดับ (Underemployment) ซึ่งทำงานต่ำกว่า 35 ชั่วโมงต่อสัปดาห์ หรือการทำงานในภาคเศรษฐกิจนอกระบบ (Informal Sector) ซึ่งอาจไม่ตรงกับนิยามของสำนักงานสถิติแห่งชาติ และทำให้เกิดความคลาดเคลื่อนในการแปลความหมาย นอกจากนี้ควรพิจารณาเลือกใช้ตัวแปรอื่นๆ มาศึกษาเพิ่มเติม อย่างเช่น ข้อมูลการขึ้นทะเบียนผู้ประกันตนกรณีว่างงาน ข้อมูลการหางานหรือการเปิดรับสมัครงานผ่านเว็บไซต์หางาน ฯลฯ
- ในด้านแบบจำลองการพยากรณ์ ควรมีความหลากหลายมากยิ่งขึ้น เพื่อให้ได้แบบจำลองที่มีความคลาดเคลื่อนน้อยลงหรือมีความเหมาะสมมากยิ่งขึ้น เช่น การประยุกต์ใช้วิธีการด้าน Machine Learning ในการพยากรณ์ และการปรับข้อมูลคุณลักษณะก่อนนำมาใช้ในการพยากรณ์ด้วยวิธีการอื่นๆ เช่น Principal Component Analysis เป็นต้น
รายการอ้างอิง
Antenucci, D., Cafarella, M., Levenstein, M., Ré, C., & Shapiro, M. D. (2014). Using Social Media to
Measure Labor Market Flows. National Bureau of Economic Research Working Paper Series,
No. 20010. doi:10.3386/w20010
Bank of Thailand. (2020). Unemployment rate by region. Retrieved February 27, 2020 from
https://www.bot.or.th/App/BIZSHR/stat/DataSeries/30
Becketti, S. (2013). Introduction to time series using Stata. College Station, Texas :: Stata Press.
Electronic Transactions Development Agency, Ministry of Digital Economy and Society. (2020).
Thailand Internet User Behavior 2019. (n.p.): (n.p.).
Enders, W. (2010). Applied econometric time series. Hoboken, N.J. :: Wiley.
Kanungsukkasem, N., & Leelanupab, T. (2014). The correlations between Twitter data
and financial instruments. KMITL Information Technology Journal, 3(2), Retrieved November
13, 2019 from http://www.it.kmitl.ac.th/~journal/index.php/main_journal/article/view/30/28
Llorente, A., Garcia-Herranz, M., Cebrian, M., & Moro, E. (2015). Social Media Fingerprints of
Unemployment. PLOS ONE, 10(5), e0128692. doi:10.1371/journal.pone.0128692
McLaren, N., & Shanbhogue, R. (2011). Using internet search data as economic indicators. Bank of
England Quarterly Bulletin, 51(2), 134-140.
Nakavachara, V., & Lekfuangfu, N. W. (2018). Predicting the Present Revisited: The Case of Thailand.
Thailand and The World Economy, 36(3), 23-46. Retrieved November 13, 2019, from
https://so05.tci-thaijo.org/index.php/TER/article/view/162339
National Statistical Office. (2019). THE LABOR FORCE SURVEY WHOLE KINGDOM QUARTER 2 :
APRIL-JUNE 2019. Bangkok: National Statistical Office.
National Statistical Office. (2020). THE LABOR FORCE SURVEY WHOLE KINGDOM. Retrieved
February 27, 2020 from http://www.nso.go.th/sites/2014/DocLib13/Forms/AllItems.aspx?
RootFolder=%2fsites%2f2014%2fDocLib13%2fด้านสังคม%2fสาขาแรงงาน%2fภาวะการทำงานของ
ประชากร
Piet, J. H. D., & Marco, J. H. P. (2014). Social media sentiment and consumer confidence (978-92-899-
1403-1). Retrieved November 13, 2019, from http://hdl.handle.net/10419/154640
Rangkakulnuwat, P. (2013). Time series analysis for economics and business. Bangkok:
Chulalongkorn University Press.
Ruiz, E., Hristidis, V., Castillo, C., Gionis, A., & Jaimes, A. (2012). Correlating Financial Time Series
with Micro-Blogging Activity.
Sala, C. (2008). Basic principles of labour economics. Bangkok: Chulalongkorn University Press.
Sawaengsuksant, P. (2018). Monitoring the economy with Google search volumes. Focus and Quick,
125, 1-8. Retrieved November 13, 2019 from https://www.bot.or.th/Thai/MonetaryPolicy/
ArticleAndResearch/FAQ/FAQ_125.pdf
Soonthornchawakan, N, (2016). Labor economics. Pathum Thani: Thammasat Printing House.
Statcounter. (2020). Search Engine Market Share Worldwide 2019. Retrieved February 27, 2020, from
https://gs.statcounter.com/search-engine-market-share#yearly-2019-2019-bar
Taesombat, T. (2006). Quantitative forecasting. Bangkok: Kasetsart University Press.
Tangkrachang, A. (2003).Managerial economics. Bangkok: Dharmasarn Printing Company Limited.

ธนัตถ์พราว ลีลารัตน์
คณะเศรษฐศาสตร์ มหาวิทยาลัยธรรมศาสตร์
ผู้เขียน

ผศ.ดร. ณัฐพงษ์ พัฒนพงษ์
คณะเศรษฐศาสตร์ มหาวิทยาลัยธรรมศาสตร์
ผู้เขียน

ผศ.ดร. วศิน ศิวสฤษดิ์
คณะเศรษฐศาสตร์ มหาวิทยาลัยธรรมศาสตร์
ผู้เขียน